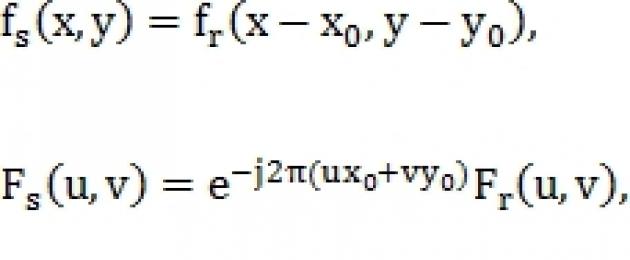
Рис. 1. Результат движения головы и глаза при сканировании сетчатки.
Влияние изменения масштаба на сравнение сетчаток не так критично, как влияние других параметров, поскольку положение головы и глаза более или менее зафиксировано по оси, соответствующей масштабу. В случае, когда масштабирование всё же есть, оно столь мало, что не оказывает практически никакого влияния на сравнение сетчаток. Таким образом, основным требованием к алгоритму является устойчивость к вращению и смещению сетчатки.
Алгоритмы аутентификации по сетчатке глаза можно разделить на два типа: те, которые для извлечения признаков используют алгоритмы сегментации (алгоритм, основанный на методе фазовой корреляции; алгоритм, основанный на поиске точек разветвления) и те, которые извлекают признаки непосредственно с изображения сетчатки (алгоритм, использующий углы Харриса).
1. Алгоритм, основанный на методе фазовой корреляции
Суть алгоритма заключается в том, что при помощи метода фазовой корреляции оцениваются смещение и вращение одного изображения относительно другого. После чего изображения выравниваются и вычисляется показатель их схожести.В реализации метод фазовой корреляции работает с бинарными изображениями, однако может применяться и для изображений в 8-битном цветовом пространстве.
Пусть и – изображения, одно из которых сдвинуто на относительно другого, а и – их преобразования Фурье, тогда:

Где – кросс-спектр;
– комплексно сопряженное
Вычисляя обратное преобразование Фурье кросс-спектра, получим импульс-функцию:
Найдя максимум этой функции, найдём искомое смещение.
Теперь найдём угол вращения при наличии смещения , используя полярные координаты:

Данная техника не всегда показывает хорошие результаты на практике из-за наличия небольших шумов и того, что часть сосудов может присутствовать на одном изображении и отсутствовать на другом. Чтобы это устранить применяется несколько итераций данного алгоритма, в том числе меняется порядок подачи изображений в функцию и порядок устранения смещения и вращения. На каждой итерации изображения выравниваются, после чего вычисляется их показатель схожести, затем находится максимальный показатель схожести, который и будет конечным результатом сравнения.
Показатель схожести вычисляется следующим образом:
2. Алгоритм, использующий углы Харриса
Данный алгоритм, в отличие от предыдущего, не требует сегментации сосудов, поскольку может определять признаки не только на бинарном изображении.В начале изображения выравниваются при помощи метода фазовой корреляции, описанного в предыдущем разделе. Затем на изображениях ищутся углы Харриса (рис. 2).

Рис. 2. Результат поиска углов Харриса на изображениях сетчатки.
Пусть найдена M+1 точка, тогда для каждой j-й точки её декартовы координаты преобразуются в полярные и определяется вектор признаков где

Модель подобия между неизвестным вектором и вектором признаков размера N в точке j определяется следующим образом:

Где – константа, которая определяется ещё до поиска углов Харриса.
Функция описывает близость и похожесть вектора ко всем признакам точки j.
Пусть вектор – вектор признаков первого изображения, где размера K–1, а вектор – вектор признаков второго изображения, где размера J–1, тогда показатель схожести этих изображений вычисляется следующим образом:

Нормировочный коэффициент для similarity равняется
Коэффициент в оригинальной статье предлагается определять по следующему критерию: если разница между гистограммами изображений меньше заранее заданного значения, то = 0.25, в противном случае = 1.
3. Алгоритм, основанный на поиске точек разветвления
Данный алгоритм, как и предыдущий, ищет точки разветвления у системы кровеносных сосудов. При этом он более специализирован на поиске точек бифуркации и пересечения (рис. 3) и намного более устойчив к шумам, однако может работать только на бинарных изображениях.
Рис. 3. Типы признаков (слева – точка бифуркации, справа – точка пересечения).
Для поиска точек, как на рис. 3, сегментированные сосуды сжимаются до толщины одного пикселя. Таким образом, можно классифицировать каждую точку сосудов по количеству соседей S:
- если S = 1, то это конечная точка;
- если S = 2, то это внутренняя точка;
- если S = 3, то это точка бифуркации;
- если S = 4, то это точка пересечения.
3.1. Алгоритм сжатия сосудов до толщины одного пикселя и классификация точек разветвления
Вначале выполняется поиск пикселя, являющегося частью сосуда, сверху вниз слева направо. Предполагается, что каждый пиксель сосуда может иметь не более двух соседних пикселей сосудов (предыдущий и следующий), во избежание двусмысленности в последующих вычислениях.Далее анализируются 4 соседних пикселя найденной точки, которые ещё не были рассмотрены. Это приводит к 16 возможным конфигурациям (рис. 4). Если пиксель в середине окна не имеет соседей серого цвета, как показано на рис. 4 (a), то он отбрасывается и ищется другой пиксель кровеносных сосудов. В других случаях это либо конечная точка, либо внутренняя (не включая точки бифуркации и пересечения).

Рис. 4. 16 возможных конфигураций четырёх соседних пикселей (белые точки – фон, серые – сосуды). 3 верхних пикселя и один слева уже были проанализированы, поэтому игнорируются. Серые пиксели с крестиком внутри также игнорируются. Точки со стрелочкой внутри – точки, которые могут стать следующим центральным пикселем. Пиксели с чёрной точкой внутри – это конечные точки.
На каждом шаге сосед серого цвета последнего пикселя помечается как пройденный и выбирается следующим центральным пикселем в окошке 3 x 3. Выбор такого соседа определяется следующим критерием: наилучший сосед тот, у которого наибольшее количество непомеченных серых соседей. Такая эвристика обусловлена идеей поддержания однопиксельной толщины в середине сосуда, где большее число соседей серого цвета.
Из вышеизложенного алгоритма следует, что он приводит к разъединению сосудов. Также сосуды могут разъединиться ещё на этапе сегментации. Поэтому необходимо соединить их обратно.
Для восстановления связи между двумя близлежащими конечными точками определяются углы и как на рис. 5, и если они меньше заранее заданного угла то конечные точки объединяются.

Рис. 5. Объединение конечных точек после сжатия.
Чтобы восстановить точки бифуркации и пересечения (рис. 6) для каждой конечной точки вычисляется её направление, после чего производится расширение сегмента фиксированной длины Если это расширение пересекается с другим сегментом, то найдена точка бифуркации либо пересечения.

Рис. 6. Восстановление точки бифуркации.
Точка пересечения представляет собой две точки бифуркации, поэтому для упрощения задачи можно искать только точки бифуркации. Чтобы удалить ложные выбросы, вызванные точками пересечения, можно отбрасывать точки, которые находится слишком близко к другой найденной точке.
Для нахождения точек пересечения необходим дополнительный анализ (рис. 7).

Рис. 7. Классификация точек разветвления по количеству пересечений сосудов с окружностью. (a) Точка бифуркации. (b) Точка пересечения.
Как видно на рис. 7 (b), в зависимости от длины радиуса окружность с центром в точке разветвления может пересекаться с кровеносными сосудами либо в трех, либо в четырёх точках. Поэтому точка разветвления может быть не правильно классифицирована. Чтобы избавиться от этой проблемы используется система голосования, изображённая на рис. 8.

Рис. 8. Схема классификации точек бифуркации и пересечения.
В этой системе голосования точка разветвления классифицируется для трёх различных радиусов по количеству пересечений окружности с кровеносными сосудами. Радиусы определяются как: где и принимают фиксированные значения. При этом вычисляются два значения и означающие количество голосов за то, чтобы точка была классифицирована как точка пересечения и как точка бифуркации соответственно:

Где и – бинарные значения, указывающие идентифицирована ли точка с использованием радиуса как точка пересечения либо как точка бифуркации соответственно.
В случае если то тип точки не определён. Если же значение отличаются друг от друга, то при точка классифицируется как точка пересечения, в противном случае как точка бифуркации.
3.2. Поиск преобразования подобия и определение метрики схожести
После того, как точки найдены, необходимо найти преобразование подобия. Это преобразование описывается 4 параметрами – смещение по оси и , масштаб и вращение соответственно.Само преобразование определяется как:

Где – координаты точки на первом изображении
– на втором изображении
Для нахождения преобразования подобия используются пары контрольных точек. Например, точки определяют вектор где – координаты начала вектора, – длина вектора и – направление вектора. Таким же образом определяется вектор для точек Пример представлен на рис. 9.

Рис. 9. Пример двух пар контрольных точек.
Параметры преобразования подобия находятся из следующих равенств:

Пусть количество найденных точек на первом изображения равняется M, а на втором N, тогда количество пар контрольных точек на первом изображении равно а на втором Таким образом, получаем ![]() возможных преобразований, среди которых верным выбирается то, при котором количество совпавших точек наибольшее.
возможных преобразований, среди которых верным выбирается то, при котором количество совпавших точек наибольшее.
Поскольку значение параметра S близко к единице, то T можно уменьшить, отбрасывая пары точек, неудовлетворяющие следующему неравенству:
![]()
Где – это минимальный порог для параметра
– это максимальный порог для параметра
– пара контрольных точек из
– пара контрольных точек из
После применения одного из возможных вариантов выравнивания для точек и вычисляется показатель схожести:
![]()
Где – пороговая максимальная дистанция между точками.
В случае если то
В некоторых случаях обе точки могут иметь хорошее значение похожести с точкой . Это случается, когда и находятся близко друг к другу. Для определения наиболее подходящей пары вычисляется вероятность схожести:
Где
Если то
Чтобы найти количество совпавших точек строится матрица Q размера M x N так, что в i-й строке и j-м столбце содержится
Затем в матрице Q ищется максимальный ненулевой элемент. Пусть этот элемент содержится в -й строке и -м столбце, тогда точки и определяются как совпавшие, а -я строка и -й столбец обнуляются. После чего опять ищется максимальный элемент. Поиск таких максимумов повторяется до тех пор, пока все элементы матрицы Q не обнулятся. На выходе алгоритма получаем количество совпавших точек C.
Метрику схожести двух сетчаток можно определить несколькими способами:
Где – параметр, который вводится для настройки влияния количества совпавших точек;
f выбирается одним из следующих вариантов:

Метрика нормализуется одним из двух способов:

Где и – некоторые константы.
3.3. Дополнительные усложнения алгоритма
Метод, основанный на поиске точек разветвления, можно усложнить, добавляя дополнительные признаки, например углы, как на рис. 10.
Рис. 10. Углы, образованные точками разветвления, в качестве дополнительных признаков.
Также можно применять шифр гаммирования. Как известно, сложение по модулю 2 является абсолютно стойким шифром, когда длина ключа равна длине текста, а поскольку количество точек бифуркации и пересечения не превышает порядка 100, но всё же больше длины обычных паролей, то в качестве ключа можно использовать комбинацию хешей пароля. Это избавляет от необходимости хранить в базе данных сетчатки глаза и хеши паролей. Нужно хранить только координаты, зашифрованные абсолютно стойким шифром.
Заключение
Аутентификация по сетчатке действительно показывает точные результаты. Алгоритм, основанный на методе фазовой корреляции, не допустил ни одной ошибки при тестировании на базе данных VARIA. Также алгоритм был протестирован на неразмеченной базе MESSIDOR с целью проверки алгоритма на ложные срабатывания. Все найденные алгоритмом пары похожих сетчаток были проверены вручную. Они действительно являются одинаковыми. На сравнение кровеносных сосудов двух сетчаток глаз из базы VARIA уходит в среднем 1.2 секунды на двух ядрах процессора Pentium Dual-CoreT4500 с частотой 2.30 GHz. Время исполнения алгоритма получилось довольно большое для идентификации, но оно приемлемо для аутентификации.Также была предпринята попытка реализации алгоритма, использующего углы Харриса, но получить удовлетворительных результатов не удалось. Как и в предыдущем алгоритме, возникла проблема в устранении вращения и смещения при помощи метода фазовой корреляции. Вторая проблема связана с недостатками алгоритма поиска углов Харриса. При одном и том же пороговом значении для отсева точек, количество найденных точек может оказаться либо слишком большим либо слишком малым.
В дальнейших планах стоит разработка алгоритма, основанного на поиске точек разветвления. Он требует гораздо меньше вычислительных ресурсов по сравнению с алгоритмом, основанном на методе фазовой корреляции. Кроме того, существуют возможности для его усложнения в целях сведения к минимуму вероятности взлома системы.
Другим интересным направлением в дальнейших исследованиях является разработка автоматических систем для ранней диагностики заболеваний, таких как глаукома, сахарный диабет, атеросклероз и многие другие.
P.s. по немногочисленным просьбам выкладываю
Профилактические осмотры помогают диагностировать многие заболевания на ранних стадиях, однако некоторые из них могут быть обнаружены лишь тогда, когда болезнь уже запущена.
Кроме того, некоторые опасные для жизни патологии не могут быть выявлены в далёких от столицы регионах из-за отсутствия квалифицированных врачей. Изменить сложившееся положения дел могут учёные из Медицинского университета Вены, которые представили доступный сканер сетчатки глаза. С его помощью можно осуществлять раннюю диагностику многих заболеваний, в том числе и сахарного диабета.
Как это работает
Согласно изданию Science Daily, для своей разработки исследователи использовали данные, которые можно «считать» с сетчатки глаза любого человека, а информации она может дать немало. При разработке сканера использовалась технология оптической когерентной томографии (ОКТ), которая в течение 1,2 секунды производит до 40 000 снимков. Полученные данные анализируются алгоритмами на основе искусственного интеллекта, а после система выдает заключение.
Что можно обнаружить
Как удалось выяснить, такой метод диагностики без помощи врача-офтальмолога дает возможность выявить наличие у пациента диабета или же вычислить риск его появления, кроме того, можно получить данные о биологическом возрасте, склонности и стаже курения и еще ряде параметров. В обозримом будущем ученые планируют усовершенствовать алгоритм с целью диагностики возрастных дегенеративных нарушений, неврологических проблем, заболеваний почек, сердца и сосудов, печени, а также патологии остальных внутренних органов.
Цена которого составляет всего $229,99. Это первый в мире смартфон который будет оснащен технологией распознавания глаза 2-го поколения.
Однако, когда речь идет о распознавании радужки глаза, люди склонны путать его с другим видом технологии идентификации под названием “сканирование сетчатки”. Сегодня в этой статье мы хотели бы обсудить сходства и различия в деталях между видами сканирования глаз.
Как определяются две технологии идентификации на основе глаз?
Распознавание радужки глаза
Распознавание радужки глаза, как биологическая система аутентификации, представляет собой автоматизированный метод, который использует математические методы распознавания образов на видеоизображении одного или обоих зрачков глаз индивидуума, чей комплекс случайных моделей являются уникальными, стабильными, и их можно увидеть с некоторого расстояния.
Сканирование сетчатки
Сканирование сетчатки – это совсем другое, основана но глазной биометрической технологии, которая использует уникальные узоры на сетчатке глаза кровеносных сосудов человека. Человеческая сетчатка представляет собой тонкую ткань которая состоит из нервных клеток, расположенных в задней части глаза.
Сходства между распознаванием радужки и сканированием сетчатки глаза.
В биометрии, радужная оболочка и сканирование сетчатки глаза являются “глазной основой” технологии идентификации, которые основаны на уникальных физиологических характеристиках глаза для идентификации личности.
Разница для лучшего понимания
Хоть сканирование радужной оболочки и сетчатки глаза являются “глазно-основанными” биометрическими технологиями,есть еще определенные различия, которые помогут различить два метода. Радужная оболочка глаза всегда описывается как идеальная часть человеческого тела для биометрической идентификации. Причины указанны ниже:
- Распознавание радужки глаза применяет алгоритм, который может идентифицировать до 200 точек в том числе кольца, борозды и веснушек внутри радужной оболочки, гораздо более точно чем любая другая технология биометрической идентификации. Таким образом, технология распознавания радужной оболочки рассматривается как технология биометрической идентификации высокой точности. Она позволит значительно снизить уровень ложных совпадений и усилит безопасность личной жизни.
- Радужная оболочка каждого человека уникальна и текстура остается удивительно стабильной, которая вряд ли может измениться в течении как минимум двух лет. Точность измерения может зависеть от заболевания.
- Распознавание радужки глаза позволяет разблокировать ваш телефон более удобно и быстро. Возьмите свой телефон, сканируйте радужную оболочку, и ваш телефон будет разблокирован в течении одной секунды, быстрее и гораздо удобнее, чем когда-либо. Распознавание радужки глаза ничем не сложнее, чем фотографирование и занимает всего секунду, чтобы разблокировать телефон.
- Говорят, что сканирование сетчатки глаза вредно из-за видимого света в глаза; и некоторые ограничения будут происходить в темноте. В то же время, распознаванию радужки глаза нужно всего сделать фотографию для идентификации и так же годна для использования в темной окружающей среде, например в низкой освещенности в помещении или ночью.

Что же касается других преимуществ Распознавание радужки глаза , есть гораздо больше пунктов о которых заслуженно следует упомянуть. С запуском HOMTOM HT10 это принесет более экстраординарный и удивительный опыт для всех.
Технология сканирования радужной оболочки глаза была впервые предложена в 1936 году офтальмологом Франком Буршем. Он заявил, что радужная оболочка глаза каждого человека является уникальной. Вероятность ее совпадения составляет примерно 10 в минус 78-ой степени, что значительно выше, чем при дактилоскопии. Согласно теории вероятности, за всю историю человечества еще не было двух людей, у которых бы совпал узор глаза. В начале 90-х Джон Дафман из компании Iridian Technologies запатентовал алгоритм для обнаружения различий радужной оболочки глаза. На данный момент этот способ биометрической аутентификации является одним из наиболее эффективных и производится с помощью специального сенсора - иридосканера.
Радужная оболочка глаза - это тонкая подвижная диафрагма со зрачком в центре, которая расположена за роговицей перед хрусталиком глаза. Она образовывается ещё до рождения человека и не меняется на протяжении всей жизни. По текстуре радужная оболочка напоминает сеть с большим количеством кругов, при этом ее рисунок очень сложен, что позволяет отобрать порядка 200 точек, с помощью которых обеспечивается высокая степень надежности аутентификации.
Сканер радужной оболочки глаза часто ошибочно называют сканером сетчатки. Отличие заключается в том, что сетчатка расположена внутри глаза и просканировать ее оптическим сенсором невозможно, только с помощью инфракрасного излучения. При этом анализируется не сама сетчатка, а узор кровеносных сосудов глазного дна. Называть подобный сенсор иридосканером неправильно, так как iris – это радужка, сетчатка же имеет название retina.

В основе иридосканера современного смартфона лежит высококонтрастная камера, подобная обычной камере. Иногда роль сканера радужной оболочки может выполнять и обычная фронтальная камера. Процесс аутентификации начинается с получения детального изображения глаза человека. Для этой цели используют монохромную камеру с неяркой подсветкой, которая чувствительна к инфракрасному излучению и позволяет работать в условиях недостаточной освещенности. Обычно делается серия из нескольких фотографий, так как зрачок чувствителен к свету и постоянно меняет свой размер. Затем из полученных фотографий выбирается одна наиболее удачная, определяются границы радужки и контрольная область. К каждой точке выбранной области применяют специальные фильтры, чтобы извлечь фазовую информацию и преобразовать рисунок оболочки в цифровой формат. Очки и контактные линзы, даже цветные, не влияют на качество аутентификации.

Внедрение сканера радужной оболочки глаза в смартфоны началось в 2015 году. Первыми его стали устанавливать китайские и японские производители. В частности первопроходцем был ViewSonic V55, так и не поступивший в массовую продажу. Из самых новых устройств, оснащенных иридосканером, можно выделить Samsung Galaxy S8, однако его сканер с легкостью удалось обмануть хакерам, распечатавшим фотографию на принтере и положившим на нее контактную линзу.