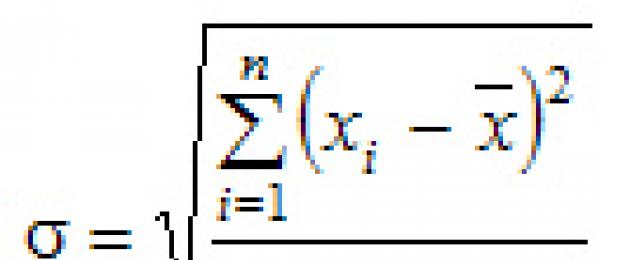
La caratteristica più perfetta della variazione è la deviazione quadratica media, chiamata standard (o deviazione standard). Deviazione standard() è uguale alla radice quadrata della deviazione quadrata media dei singoli valori dell'attributo dalla media aritmetica:
La deviazione standard è semplice:


La deviazione standard ponderata viene applicata ai dati raggruppati:

Tra il valore quadratico medio e le deviazioni lineari medie in condizioni di distribuzione normale si verifica il seguente rapporto: ~ 1,25.
La deviazione standard, essendo la principale misura assoluta di variazione, viene utilizzata per determinare i valori ordinati di una curva di distribuzione normale, nei calcoli relativi all'organizzazione dell'osservazione del campione e per stabilire l'accuratezza delle caratteristiche del campione, nonché nella valutazione della limiti di variazione di una caratteristica in una popolazione omogenea.
Dispersione, sue tipologie, deviazione standard.
Varianza di una variabile casuale— una misura della diffusione di una determinata variabile casuale, ovvero la sua deviazione dall'aspettativa matematica. Nelle statistiche viene spesso utilizzata la notazione o . La radice quadrata della varianza è chiamata deviazione standard, deviazione standard o spread standard.
Varianza totale (σ2) misura la variazione di un tratto nel suo complesso sotto l'influenza di tutti i fattori che hanno causato tale variazione. Allo stesso tempo, grazie al metodo del raggruppamento, è possibile identificare e misurare la variazione dovuta alle caratteristiche del raggruppamento e la variazione derivante dall'influenza di fattori non contabilizzati.
Varianza intergruppo (σ 2 m.gr) caratterizza la variazione sistematica, cioè le differenze nel valore della caratteristica studiata che sorgono sotto l'influenza della caratteristica, il fattore che costituisce la base del gruppo.
Deviazione standard(sinonimi: deviazione standard, deviazione standard, deviazione quadrata; termini correlati: deviazione standard, diffusione standard) - nella teoria e nella statistica della probabilità, l'indicatore più comune della dispersione dei valori di una variabile casuale rispetto alla sua aspettativa matematica. Con matrici limitate di campioni di valori, invece dell'aspettativa matematica, viene utilizzata la media aritmetica dell'insieme di campioni.
La deviazione standard è misurata in unità della variabile casuale stessa e viene utilizzata quando si calcola l'errore standard della media aritmetica, quando si costruiscono intervalli di confidenza, quando si testano statisticamente le ipotesi, quando si misura la relazione lineare tra variabili casuali. Definito come la radice quadrata della varianza di una variabile casuale.
Deviazione standard:

Deviazione standard(stima della deviazione standard di una variabile casuale X rispetto alla sua aspettativa matematica basata su una stima imparziale della sua varianza):

dov'è la dispersione; — io elemento della selezione; - misura di prova; — media aritmetica del campione:
![]()
Va notato che entrambe le stime sono distorte. Nel caso generale, è impossibile costruire una stima imparziale. Tuttavia, la stima basata sulla stima imparziale della varianza è coerente.
Essenza, ambito e procedura per la determinazione della moda e della mediana.
Oltre alle medie di potenza in statistica, per la caratterizzazione relativa del valore di una caratteristica variabile e la struttura interna delle serie di distribuzione, vengono utilizzate le medie strutturali, rappresentate principalmente da moda e mediana.
Moda- Questa è la variante più comune della serie. La moda viene utilizzata, ad esempio, per determinare la taglia dei vestiti e delle scarpe più richieste dagli acquirenti. La modalità per una serie discreta è quella con la frequenza più alta. Quando si calcola la moda per una serie di variazioni di intervallo, è necessario prima determinare l'intervallo modale (basato sulla frequenza massima), quindi il valore del valore modale dell'attributo utilizzando la formula:

- - valore della moda
- — limite inferiore dell'intervallo modale
- - dimensione dell'intervallo
- — frequenza dell'intervallo modale
- — frequenza dell'intervallo che precede il modale
- — frequenza dell'intervallo successivo al modale
Mediano - questo è il valore dell'attributo che sta alla base della serie classificata e divide questa serie in due parti uguali.
Per determinare la mediana in una serie discreta in presenza di frequenze, calcolare prima la semisomma delle frequenze e poi determinare quale valore della variante cade su di essa. (Se la serie ordinata contiene un numero dispari di elementi, il numero mediano viene calcolato utilizzando la formula:
M e = (n (numero di caratteristiche in totale) + 1)/2,
nel caso di un numero pari di caratteristiche, la mediana sarà pari alla media delle due caratteristiche al centro della riga).
Durante il calcolo mediane per una serie di variazioni di intervallo, determinare innanzitutto l'intervallo mediano all'interno del quale si trova la mediana, quindi determinare il valore della mediana utilizzando la formula:

- — la mediana richiesta
- - limite inferiore dell'intervallo che contiene la mediana
- - dimensione dell'intervallo
- — somma delle frequenze o numero dei termini della serie
Somma delle frequenze accumulate degli intervalli che precedono la mediana
- — frequenza dell'intervallo mediano
Esempio. Trova la moda e la mediana.
Soluzione:
In questo esempio, l'intervallo modale rientra nella fascia di età 25-30 anni, poiché questo intervallo ha la frequenza più alta (1054).
Calcoliamo l'entità della modalità:
Ciò significa che l’età modale degli studenti è di 27 anni.
Calcoliamo la mediana. L'intervallo mediano è nella fascia di età 25-30 anni, poiché all'interno di questo intervallo esiste un'opzione che divide la popolazione in due parti uguali (Σf i /2 = 3462/2 = 1731). Successivamente, sostituiamo i dati numerici necessari nella formula e otteniamo il valore mediano:

Ciò significa che la metà degli studenti ha meno di 27,4 anni e l'altra metà ha più di 27,4 anni.
Oltre alla moda e alla mediana, possono essere utilizzati indicatori come i quartili, dividendo la serie classificata in 4 parti uguali, decili- 10 parti e percentili - per 100 parti.
Il concetto di osservazione selettiva e la sua portata.
Osservazione selettiva si applica quando si utilizza la sorveglianza continua fisicamente impossibile a causa di una grande quantità di dati o non economicamente fattibile. L'impossibilità fisica si verifica, ad esempio, quando si studiano i flussi di passeggeri, i prezzi di mercato e i bilanci familiari. L'inopportunità economica si verifica quando si valuta la qualità dei beni associati alla loro distruzione, ad esempio assaggiando, testando la resistenza dei mattoni, ecc.
Le unità statistiche selezionate per l'osservazione costituiscono il quadro di campionamento o campione, e il loro intero insieme costituisce la popolazione generale (GS). In questo caso, il numero di unità nel campione è indicato con N, e nell'intero SA - N. Atteggiamento n/N chiamata dimensione relativa o proporzione del campione.
La qualità dei risultati dell'osservazione del campione dipende dalla rappresentatività del campione, cioè da quanto è rappresentativo nel sistema sanitario. Per garantire la rappresentatività del campione, è necessario conformarsi principio della selezione casuale delle unità, che presuppone che l'inclusione di un'unità HS nel campione non possa essere influenzata da alcun altro fattore se non dal caso.
Esiste 4 modi di selezione casuale campionare:
- In realtà casuale selezione o “metodo del lotto”, in cui a quantità statistiche vengono assegnati numeri di serie, registrati su determinati oggetti (ad esempio, barili), che vengono poi mescolati in qualche contenitore (ad esempio, in una borsa) e selezionati in modo casuale. In pratica, questo metodo viene eseguito utilizzando un generatore di numeri casuali o tabelle matematiche di numeri casuali.
- Meccanico selezione in base alla quale ciascuno ( N/n)-esimo valore della popolazione generale. Ad esempio, se contiene 100.000 valori ed è necessario selezionarne 1.000, nel campione verrà incluso ogni 100.000/1.000 = 100esimo valore. Inoltre, se non sono classificati, il primo verrà selezionato a caso tra i primi cento e il numero degli altri sarà cento più alto. Ad esempio, se la prima unità fosse la n. 19, la successiva dovrebbe essere la n. 119, poi la n. 219, poi la n. 319, ecc. Se le unità di popolazione vengono classificate, viene selezionato per primo il n. 50, poi il n. 150, poi il n. 250 e così via.
- Viene eseguita la selezione di valori da un array di dati eterogeneo stratificato metodo (stratificato), quando la popolazione viene prima divisa in gruppi omogenei ai quali viene applicata la selezione casuale o meccanica.
- Un metodo di campionamento speciale è seriale selezione, in cui selezionano casualmente o meccanicamente non valori individuali, ma le loro serie (sequenze da un numero a un numero di seguito), all'interno delle quali viene effettuata l'osservazione continua.
Dipende anche dalla qualità delle osservazioni del campione tipo di campione: ripetuto O irripetibile.
A riselezione I valori statistici o le loro serie inclusi nel campione vengono restituiti alla popolazione generale dopo l'uso, avendo la possibilità di essere inclusi in un nuovo campione. Inoltre, tutti i valori della popolazione hanno la stessa probabilità di inclusione nel campione.
Selezione infinita significa che i valori statistici o le loro serie inclusi nel campione non ritornano alla popolazione generale dopo l’uso, e quindi per i restanti valori di quest’ultimo aumenta la probabilità di essere inclusi nel campione successivo.
Il campionamento non ripetitivo fornisce risultati più accurati, quindi viene utilizzato più spesso. Ma ci sono situazioni in cui non può essere applicato (studio dei flussi di passeggeri, della domanda dei consumatori, ecc.) e quindi viene effettuata una selezione ripetuta.
Errore massimo di campionamento dell'osservazione, errore medio di campionamento, procedura per il loro calcolo.
Consideriamo in dettaglio i metodi sopra elencati per formare una popolazione campione e gli errori che si verificano nel farlo. rappresentatività .
Giustamente casuale il campionamento si basa sulla selezione casuale di unità dalla popolazione senza elementi sistematici. Tecnicamente, la selezione casuale effettiva viene effettuata mediante estrazione a sorte (ad esempio, lotterie) o utilizzando una tabella di numeri casuali.
La corretta selezione casuale “nella sua forma pura” è usata raramente nella pratica dell’osservazione selettiva, ma è l’originale tra gli altri tipi di selezione, implementa i principi di base dell’osservazione selettiva. Consideriamo alcune domande sulla teoria del metodo di campionamento e sulla formula dell'errore per un campione casuale semplice.
Distorsione del campionamentoè la differenza tra il valore del parametro nella popolazione generale e il suo valore calcolato dai risultati dell'osservazione del campione. Per una caratteristica quantitativa media, l'errore di campionamento è determinato da
L’indicatore è chiamato errore marginale di campionamento.
La media campionaria è una variabile casuale che può assumere valori diversi a seconda di quali unità sono incluse nel campione. Pertanto anche gli errori di campionamento sono variabili casuali e possono assumere valori diversi. Pertanto, viene determinata la media dei possibili errori: errore medio di campionamento, che dipende da:
Dimensione del campione: maggiore è il numero, minore è l'errore medio;
Il grado di cambiamento della caratteristica studiata: minore è la variazione della caratteristica e, di conseguenza, la dispersione, minore è l'errore medio di campionamento.
A riselezione casuale si calcola l'errore medio:
.
In pratica la varianza generale non è nota con precisione, ma in teoria della probabilitàè stato dimostrato ![]() .
.
Poiché il valore di n sufficientemente grande è vicino a 1, possiamo supporre che . Successivamente si può calcolare l’errore medio di campionamento:
.
Ma nei casi di campione piccolo (con n<30) коэффициент необходимо учитывать, и среднюю ошибку малой выборки рассчитывать по формуле  .
.
A campionamento casuale non ripetitivo le formule fornite vengono regolate dal valore . Allora l’errore medio di campionamento non ripetitivo è:  E
E  .
.
Perché è sempre inferiore, allora il moltiplicatore () è sempre inferiore a 1. Ciò significa che l'errore medio durante la selezione non ripetitiva è sempre inferiore rispetto a quello durante la selezione ripetuta.
Campionamento meccanico viene utilizzato quando la popolazione generale è ordinata in qualche modo (ad esempio, elenchi elettorali alfabetici, numeri di telefono, numeri civici, numeri di appartamento). La selezione delle unità viene effettuata ad un certo intervallo, che è uguale all'inverso della percentuale di campionamento. Quindi, con un campione del 2%, viene selezionata ogni 50 unità = 1/0,02, con un campione del 5%, ogni 1/0,05 = 20 unità della popolazione generale.
Il punto di riferimento viene selezionato in diversi modi: in modo casuale, dalla metà dell'intervallo, con una modifica del punto di riferimento. La cosa principale è evitare errori sistematici. Ad esempio, con un campione del 5%, se la prima unità è la 13a, le successive sono 33, 53, 73, ecc.
In termini di accuratezza, la selezione meccanica è vicina al campionamento casuale effettivo. Pertanto, per determinare l'errore medio del campionamento meccanico, vengono utilizzate apposite formule di selezione casuale.
A selezione tipica la popolazione oggetto di indagine viene preliminarmente suddivisa in gruppi omogenei e simili. Ad esempio, quando si esaminano le imprese, questi possono essere industrie, sottosettori; quando si studia la popolazione, possono essere regioni, gruppi sociali o fasce di età. Quindi viene effettuata una selezione indipendente da ciascun gruppo in modo meccanico o puramente casuale.
Il campionamento tipico produce risultati più accurati rispetto ad altri metodi. La tipizzazione della popolazione generale garantisce che ciascun gruppo tipologico sia rappresentato nel campione, il che rende possibile eliminare l'influenza della varianza intergruppo sull'errore medio di campionamento. Di conseguenza, quando si trova l'errore di un campione tipico secondo la regola della somma delle varianze (), è necessario prendere in considerazione solo la media delle varianze del gruppo. Allora l’errore medio di campionamento è:
previa riselezione
,
con selezione non ripetitiva  ,
,
Dove  - la media degli scostamenti intragruppo del campione.
- la media degli scostamenti intragruppo del campione.
Selezione seriale (o nido).
utilizzato quando la popolazione viene suddivisa in serie o gruppi prima dell'inizio dell'indagine campionaria. Queste serie possono essere confezioni di prodotti finiti, gruppi di studenti, squadre. Le serie da esaminare vengono selezionate meccanicamente o in modo puramente casuale e all'interno della serie viene effettuato un esame continuo delle unità. Pertanto, l'errore medio di campionamento dipende solo dalla varianza intergruppo (interserie), che viene calcolata con la formula: 
dove r è il numero di serie selezionate;
- media della i-esima serie.
Si calcola l'errore medio di campionamento seriale:
dopo la riselezione:
,
con selezione non ripetitiva:  ,
,
dove R è il numero totale di episodi.
Combinato selezioneè una combinazione dei metodi di selezione considerati.
L'errore medio di campionamento per qualsiasi metodo di campionamento dipende principalmente dalla dimensione assoluta del campione e, in misura minore, dalla percentuale del campione. Supponiamo che 225 osservazioni vengano effettuate nel primo caso su una popolazione di 4.500 unità e nel secondo su una popolazione di 225.000 unità. Le varianze in entrambi i casi sono pari a 25. Quindi nel primo caso, con una selezione del 5%, l'errore campionario sarà: 
Nel secondo caso, con selezione 0,1%, sarà pari a:

Così, con una diminuzione della percentuale di campionamento di 50 volte, l'errore di campionamento è leggermente aumentato, poiché la dimensione del campione non è cambiata.
Supponiamo che la dimensione del campione venga aumentata a 625 osservazioni. In questo caso l’errore di campionamento è: 
Aumentando il campione di 2,8 volte con la stessa dimensione della popolazione si riduce la dimensione dell’errore di campionamento di oltre 1,6 volte.
Metodi e metodi per formare una popolazione campione.
Nelle statistiche vengono utilizzati vari metodi per formare popolazioni campione, che sono determinati dagli obiettivi dello studio e dipendono dalle specificità dell'oggetto di studio.
La condizione principale per condurre un'indagine campionaria è quella di evitare il verificarsi di errori sistematici derivanti dalla violazione del principio di pari opportunità per ciascuna unità della popolazione generale da includere nel campione. La prevenzione degli errori sistematici si ottiene attraverso l'uso di metodi scientificamente fondati per formare una popolazione campione.
Esistono i seguenti metodi per selezionare le unità dalla popolazione:
1) selezione individuale: vengono selezionate le singole unità per il campione;
2) selezione del gruppo - il campione comprende gruppi qualitativamente omogenei o serie di unità oggetto di studio;
3) la selezione combinata è una combinazione di selezione individuale e di gruppo.
I metodi di selezione sono determinati dalle regole per formare una popolazione campione.
Il campione potrebbe essere:
- effettivamente casuale consiste nel fatto che la popolazione campione si forma come risultato della selezione casuale (non intenzionale) di singole unità dalla popolazione generale. In questo caso, il numero di unità selezionate nella popolazione campione viene solitamente determinato in base alla proporzione campionaria accettata. La proporzione campionaria è il rapporto tra il numero di unità nella popolazione campione n e il numero di unità nella popolazione generale N, cioè
- meccanico consiste nel fatto che la selezione delle unità della popolazione campione viene effettuata a partire dalla popolazione generale, divisa in intervalli uguali (gruppi). In questo caso, la dimensione dell'intervallo nella popolazione è uguale all'inverso della proporzione campionaria. Quindi, con un campione del 2%, viene selezionata ogni 50a unità (1:0,02), con un campione del 5% ogni 20a unità (1:0,05), ecc. Pertanto, secondo la proporzione accettata della selezione, la popolazione generale viene, per così dire, divisa meccanicamente in gruppi di eguali dimensioni. Da ciascun gruppo viene selezionata solo un'unità per il campione.
- tipico - in cui la popolazione generale viene prima divisa in gruppi tipici omogenei. Quindi, da ciascun gruppo tipico, viene utilizzato un campione puramente casuale o meccanico per selezionare individualmente le unità nella popolazione campione. Una caratteristica importante di un campione tipico è che fornisce risultati più accurati rispetto ad altri metodi di selezione delle unità nella popolazione campione;
- seriale- in cui la popolazione generale è divisa in gruppi di uguale dimensione - serie. Le serie vengono selezionate nella popolazione campione. All'interno della serie viene effettuata l'osservazione continua delle unità comprese nella serie;
- combinato- il campionamento può essere a due stadi. In questo caso, la popolazione viene prima divisa in gruppi. Successivamente vengono selezionati i gruppi, e all'interno di questi ultimi vengono selezionate le singole unità.
In statistica si distinguono i seguenti metodi per selezionare le unità in una popolazione campione::
- singola fase campionamento - ogni unità selezionata viene immediatamente sottoposta a studio secondo un determinato criterio (campionamento casuale e seriale vero e proprio);
- multistadio campionamento: viene effettuata una selezione dalla popolazione generale dei singoli gruppi e le singole unità vengono selezionate dai gruppi (campionamento tipico con un metodo meccanico di selezione delle unità nella popolazione campione).
Inoltre, ci sono:
- riselezione- secondo lo schema della palla restituita. In questo caso ogni unità o serie inclusa nel campione viene restituita alla popolazione generale e quindi ha la possibilità di essere nuovamente inclusa nel campione;
- ripetere la selezione- secondo lo schema della palla non restituita. Ha risultati più accurati con la stessa dimensione del campione.
Determinazione della dimensione del campione richiesta (utilizzando la tabella t di Student).
Uno dei principi scientifici della teoria del campionamento è garantire che venga selezionato un numero sufficiente di unità. Teoricamente, la necessità di rispettare questo principio è presentata nelle dimostrazioni dei teoremi limite della teoria della probabilità, che consentono di stabilire quale volume di unità dovrebbe essere selezionato dalla popolazione in modo che sia sufficiente e garantisca la rappresentatività del campione.
Una diminuzione dell'errore standard di campionamento, e quindi un aumento dell'accuratezza della stima, è sempre associata ad un aumento della dimensione del campione, pertanto, già nella fase di organizzazione dell'osservazione del campione, è necessario decidere quale sia la dimensione di la popolazione campione dovrebbe essere tale da garantire la necessaria accuratezza dei risultati dell'osservazione. Il calcolo della dimensione del campione richiesta viene costruito utilizzando formule derivate dalle formule per gli errori massimi di campionamento (A), corrispondenti a un particolare tipo e metodo di selezione. Quindi, per una dimensione del campione ripetuto casuale (n) abbiamo:

L'essenza di questa formula è che con una selezione ripetuta casuale del numero richiesto, la dimensione del campione è direttamente proporzionale al quadrato del coefficiente di confidenza (t2) e varianza della caratteristica variazionale (?2) ed è inversamente proporzionale al quadrato dell'errore massimo di campionamento (?2). In particolare, aumentando l’errore massimo di un fattore due, la dimensione del campione richiesto può essere ridotta di un fattore quattro. Dei tre parametri, due (t e?) sono impostati dal ricercatore.
Allo stesso tempo, il ricercatore, sulla base di Partendo dallo scopo e dagli obiettivi dell'indagine campionaria, occorre risolvere la domanda: in quale combinazione quantitativa è meglio includere questi parametri per garantire l'opzione ottimale? In un caso, potrebbe essere più soddisfatto dell'affidabilità dei risultati ottenuti (t) che della misura dell'accuratezza (?), nell'altro - viceversa. È più difficile risolvere la questione relativa al valore dell'errore massimo di campionamento, poiché il ricercatore non dispone di questo indicatore nella fase di progettazione dell'osservazione del campione, quindi in pratica è consuetudine impostare il valore dell'errore massimo di campionamento, solitamente entro il 10% del livello medio previsto dell'attributo. La determinazione della media stimata può essere affrontata in diversi modi: utilizzando dati provenienti da indagini precedenti simili, oppure utilizzando dati provenienti dal quadro di campionamento e conducendo un piccolo campione pilota.
La cosa più difficile da stabilire quando si progetta un'osservazione campionaria è il terzo parametro nella formula (5.2): la dispersione della popolazione campione. In questo caso, è necessario utilizzare tutte le informazioni a disposizione del ricercatore, ottenute in indagini simili e pilota precedentemente condotte.
Domanda sulla definizione la dimensione del campione richiesta diventa più complicata se l'indagine campionaria prevede lo studio di diverse caratteristiche delle unità campionarie. In questo caso, i livelli medi di ciascuna caratteristica e la loro variazione, di regola, sono diversi e, pertanto, decidere quale varianza di quale delle caratteristiche dare la preferenza è possibile solo tenendo conto dello scopo e degli obiettivi del sondaggio.
Quando si progetta un'osservazione del campione, si assume un valore predeterminato dell'errore di campionamento ammissibile in conformità con gli obiettivi di un particolare studio e la probabilità di conclusioni basate sui risultati dell'osservazione.
In generale, la formula dell’errore massimo della media campionaria permette di determinare:
L'entità delle possibili deviazioni degli indicatori della popolazione generale dagli indicatori della popolazione campione;
La dimensione del campione richiesta, garantendo la precisione richiesta, alla quale i limiti di possibile errore non supereranno un determinato valore specificato;
La probabilità che l'errore in un campione abbia un limite specificato.
Distribuzione degli studenti nella teoria della probabilità, è una famiglia ad un parametro di distribuzioni assolutamente continue.
Serie dinamica (intervallo, momento), serie dinamica di chiusura.
Serie dinamica- questi sono i valori degli indicatori statistici presentati in una determinata sequenza cronologica.
Ogni serie temporale contiene due componenti:
1) indicatori di periodi di tempo (anni, trimestri, mesi, giorni o date);
2) indicatori che caratterizzano l'oggetto in studio per periodi di tempo o in date corrispondenti, che sono chiamati livelli di serie.
I livelli della serie sono espressi sia valori assoluti che medi o relativi. A seconda della natura degli indicatori, vengono costruite serie temporali di valori assoluti, relativi e medi. Le serie dinamiche da valori relativi e medi sono costruite sulla base di serie derivate di valori assoluti. Esistono serie di dinamiche di intervalli e di momenti.
Serie di intervalli dinamici contiene valori indicatori per determinati periodi di tempo. In una serie di intervalli è possibile sommare i livelli per ottenere il volume del fenomeno su un periodo più lungo, ovvero i cosiddetti totali accumulati.
Serie di momenti dinamici riflette i valori degli indicatori in un certo momento (data dell'ora). Nelle serie momentanee, il ricercatore può essere interessato solo alla differenza nei fenomeni che riflette il cambiamento nel livello della serie tra determinate date, poiché la somma dei livelli qui non ha contenuto reale. I totali cumulativi non vengono calcolati qui.
La condizione più importante per la corretta costruzione delle serie storiche è la comparabilità dei livelli delle serie appartenenti a periodi diversi. I livelli devono essere presentati in quantità omogenee e deve esserci pari completezza di copertura delle diverse parti del fenomeno.
In modo da Per evitare distorsioni della dinamica reale, in uno studio statistico vengono effettuati calcoli preliminari (a chiusura della serie dinamica), che precedono l'analisi statistica della serie storica. Per chiusura di serie dinamiche si intende la combinazione in un'unica serie di due o più serie, i cui livelli sono calcolati utilizzando metodologie diverse o non corrispondono ai confini territoriali, ecc. La chiusura delle serie dinamiche può anche implicare il portare i livelli assoluti delle serie dinamiche su una base comune, il che neutralizza l'incomparabilità dei livelli delle serie dinamiche.
Il concetto di comparabilità delle serie dinamiche, dei coefficienti, della crescita e dei tassi di crescita.
Serie dinamica- si tratta di una serie di indicatori statistici che caratterizzano l'evoluzione dei fenomeni naturali e sociali nel tempo. Le raccolte statistiche pubblicate dal Comitato statale di statistica della Russia contengono un gran numero di serie dinamiche in forma tabellare. Le serie dinamiche consentono di identificare modelli di sviluppo dei fenomeni studiati.
Le serie dinamiche contengono due tipi di indicatori. Indicatori temporali(anni, trimestri, mesi, ecc.) o punti temporali (all'inizio dell'anno, all'inizio di ogni mese, ecc.). Indicatori di livello di riga. Gli indicatori dei livelli delle serie dinamiche possono essere espressi in valori assoluti (produzione del prodotto in tonnellate o rubli), valori relativi (quota della popolazione urbana in %) e valori medi (salari medi dei lavoratori dell'industria per anno , eccetera.). In forma tabellare, una serie temporale contiene due colonne o due righe.
La corretta costruzione delle serie storiche richiede il rispetto di una serie di requisiti:
- tutti gli indicatori di una serie di dinamiche devono essere scientificamente fondati e affidabili;
- gli indicatori di una serie di dinamiche devono essere confrontabili nel tempo, ovvero devono essere calcolati per gli stessi periodi di tempo o nelle stesse date;
- gli indicatori di alcune dinamiche devono essere comparabili sul territorio;
- gli indicatori di una serie di dinamiche devono essere comparabili nel contenuto, ovvero calcolato secondo un'unica metodologia, allo stesso modo;
- gli indicatori di una serie di dinamiche dovrebbero essere comparabili in tutta la gamma di aziende agricole prese in considerazione. Tutti gli indicatori di una serie di dinamiche devono essere espressi nelle stesse unità di misura.
Indicatori statistici può caratterizzare sia i risultati del processo studiato in un periodo di tempo, sia lo stato del fenomeno studiato in un determinato momento, vale a dire gli indicatori possono essere intervallati (periodici) e momentanei. Di conseguenza, inizialmente la serie dinamica può essere sia intervallo che momento. Le serie dinamiche dei momenti, a loro volta, possono avere intervalli di tempo uguali o disuguali.
La serie dinamica originaria può essere trasformata in una serie di valori medi e in una serie di valori relativi (a catena e di base). Tali serie temporali sono chiamate serie temporali derivate.
La metodologia per calcolare il livello medio nelle serie dinamiche è diversa, a seconda del tipo di serie dinamica. Usando esempi, considereremo i tipi di serie dinamiche e le formule per il calcolo del livello medio.
Aumenti assoluti (Δy) mostrano di quante unità è cambiato il livello successivo della serie rispetto a quello precedente (gr. 3. - incrementi assoluti di catena) o rispetto al livello iniziale (gr. 4. - incrementi assoluti di base). Le formule di calcolo possono essere scritte come segue:

Quando i valori assoluti della serie diminuiscono, si avrà rispettivamente una “diminuzione” o una “diminuzione”.
Gli indicatori di crescita assoluta indicano che, ad esempio, nel 1998, la produzione del prodotto “A” è aumentata di 4mila tonnellate rispetto al 1997, e di 34mila tonnellate rispetto al 1994; per gli altri anni vedi tabella. 11,5 gr. 3 e 4.
Tasso di crescita mostra quante volte il livello della serie è cambiato rispetto a quello precedente (gr. 5 - coefficienti di crescita o declino a catena) o rispetto al livello iniziale (gr. 6 - coefficienti base di crescita o declino). Le formule di calcolo possono essere scritte come segue:

Tassi di crescita mostrare quale percentuale è il livello successivo della serie rispetto a quello precedente (gr. 7 - tassi di crescita a catena) o rispetto al livello iniziale (gr. 8 - tassi di crescita di base). Le formule di calcolo possono essere scritte come segue:

Quindi, ad esempio, nel 1997, il volume di produzione del prodotto “A” rispetto al 1996 era del 105,5% (
Tasso di crescita mostrare in quale percentuale il livello del periodo di riferimento è aumentato rispetto a quello precedente (colonna 9 - tassi di crescita a catena) o rispetto al livello iniziale (colonna 10 - tassi di crescita di base). Le formule di calcolo possono essere scritte come segue:
T pr = T r - 100% o T pr = crescita assoluta/livello del periodo precedente * 100%
Così, ad esempio, nel 1996, rispetto al 1995, il prodotto “A” è stato prodotto del 3,8% (103,8% - 100%) o (8:210)x100% in più, e rispetto al 1994 - del 9% (109% - 100%).
Se i livelli assoluti della serie diminuiscono, il tasso sarà inferiore al 100% e, di conseguenza, si avrà un tasso di declino (il tasso di aumento con un segno meno).
In valore assoluto aumento dell'1%.(colonna 11) mostra quante unità devono essere prodotte in un dato periodo affinché il livello del periodo precedente aumenti dell'1%. Nel nostro esempio, nel 1995 è stato necessario produrre 2,0 mila tonnellate e nel 1998 - 2,3 mila tonnellate, ovvero molto più grande.
Il valore assoluto della crescita dell’1% può essere determinato in due modi:
Il livello del periodo precedente viene diviso per 100;
Dividere gli aumenti assoluti della catena per i corrispondenti tassi di crescita della catena.
Valore assoluto di aumento dell'1% = 
Nelle dinamiche, soprattutto di lungo periodo, è importante un'analisi congiunta del tasso di crescita con il contenuto di ogni aumento o diminuzione percentuale.
Si noti che la metodologia considerata per l'analisi delle serie temporali è applicabile sia alle serie temporali, i cui livelli sono espressi in valori assoluti (t, migliaia di rubli, numero di dipendenti, ecc.), sia alle serie temporali, i cui livelli sono espressi in indicatori relativi (% di difetti, % contenuto in ceneri del carbone, ecc.) o in valori medi (resa media in c/ha, salario medio, ecc.).
Insieme agli indicatori analitici considerati, calcolati per ciascun anno rispetto al livello precedente o iniziale, quando si analizzano le serie dinamiche, è necessario calcolare gli indicatori analitici medi per il periodo: il livello medio della serie, l'aumento assoluto medio annuo (diminuzione) e il tasso di crescita medio annuo e il tasso di crescita.
I metodi per calcolare il livello medio di una serie di dinamiche sono stati discussi sopra. Nella serie dinamica degli intervalli che stiamo considerando, il livello medio della serie viene calcolato utilizzando la semplice formula della media aritmetica:
Volume di produzione medio annuo del prodotto per il periodo 1994-1998. ammontavano a 218,4 mila tonnellate.
Anche la crescita media annua assoluta viene calcolata utilizzando la semplice formula della media aritmetica:
Gli aumenti assoluti annuali sono variati nel corso degli anni da 4 a 12 mila tonnellate (vedi colonna 3), e l'aumento medio annuo della produzione per il periodo 1995 - 1998. ammontavano a 8,5 mila tonnellate.
I metodi per calcolare il tasso di crescita medio e il tasso di crescita medio richiedono una considerazione più dettagliata. Consideriamoli utilizzando l'esempio degli indicatori di livello delle serie annuali riportati nella tabella.
Livello medio della serie dinamica.
Serie dinamiche (o serie temporali)- questi sono i valori numerici di un determinato indicatore statistico in momenti o periodi di tempo successivi (cioè disposti in ordine cronologico).
Vengono chiamati i valori numerici dell'uno o dell'altro indicatore statistico che costituisce la serie dinamica livelli di serie ed è solitamente indicato con la lettera sì. Primo termine della serie sì 1 chiamato iniziale o livello di base, e l'ultimo sì, no - finale. I momenti o periodi di tempo a cui si riferiscono i livelli sono designati da T.
Le serie dinamiche sono solitamente presentate sotto forma di tabella o grafico e una scala temporale è costruita lungo l'asse delle ascisse T e lungo l'asse delle ordinate - la scala dei livelli della serie sì.
Indicatori medi delle serie dinamiche
Ogni serie di dinamiche può essere considerata come un certo insieme N indicatori variabili nel tempo che possono essere riassunti come medie. Tali indicatori (medi) generalizzati sono particolarmente necessari quando si confrontano i cambiamenti di un particolare indicatore in periodi diversi, in paesi diversi, ecc.
Una caratteristica generalizzata delle serie dinamiche può servire, innanzitutto, livello della fila centrale. Il metodo per calcolare il livello medio dipende dal fatto che la serie sia momentanea o intervallata (periodica).
Quando intervallo di una serie, il suo livello medio è determinato dalla formula di una media aritmetica semplice dei livelli della serie, cioè
=
Se disponibile momento riga contenente N livelli ( y1, y2, …, yn) con intervalli uguali tra date (tempi), allora tale serie può essere facilmente convertita in una serie di valori medi. In questo caso, l'indicatore (livello) all'inizio di ciascun periodo è contemporaneamente l'indicatore alla fine del periodo precedente. Quindi il valore medio dell'indicatore per ciascun periodo (l'intervallo tra le date) può essere calcolato come metà della somma dei valori A all'inizio e alla fine del periodo, ad es. Come . Il numero di tali medie sarà . Come accennato in precedenza, per le serie di valori medi, il livello medio è calcolato utilizzando la media aritmetica.
Pertanto possiamo scrivere: .
.
Dopo aver trasformato il numeratore otteniamo: ,
,
Dove Y1 E Sì— primo e ultimo livello della fila; Sì— livelli intermedi.
Questa media è nota nelle statistiche come cronologico medio per le serie di momenti. Ha preso il nome dalla parola “cronos” (tempo, latino), poiché è calcolato da indicatori che cambiano nel tempo.
In caso di disuguaglianza intervalli tra le date, la media cronologica per una serie di momenti può essere calcolata come media aritmetica dei valori medi dei livelli per ciascuna coppia di momenti, ponderata per le distanze (intervalli di tempo) tra le date, cioè  .
.
In questo caso si presuppone che negli intervalli tra le date i livelli assumessero valori diversi, e noi siamo uno dei due conosciuti ( sì E sì+1) determiniamo le medie, da cui poi calcoliamo la media complessiva per l'intero periodo analizzato.
Se si presuppone che ciascun valore sì rimane invariato fino al successivo (io+ 1)-
l'istante, cioè Se è nota la data esatta della variazione dei livelli, il calcolo può essere effettuato utilizzando la formula della media aritmetica ponderata:
,
dove è il tempo durante il quale il livello è rimasto invariato.
Oltre al livello medio nelle serie dinamiche, vengono calcolati altri indicatori medi: la variazione media dei livelli delle serie (metodi di base e a catena), il tasso medio di variazione.
Il valore di base indica il cambiamento assolutoè il quoziente dell'ultima variazione assoluta sottostante diviso per il numero di variazioni. Questo è
Catena significa cambiamento assoluto livelli della serie è il quoziente risultante dalla divisione della somma di tutte le variazioni assolute della catena per il numero di variazioni, ovvero
Il segno delle variazioni medie assolute viene utilizzato anche per giudicare la natura del cambiamento di un fenomeno in media: crescita, declino o stabilità.
Dalla regola per controllare le variazioni assolute di base e di catena segue che le variazioni medie di base e di catena devono essere uguali.
Insieme alla variazione media assoluta, viene calcolata anche la media relativa utilizzando il metodo di base e quello a catena.
Variazione relativa media di base determinato dalla formula:
Variazione relativa media della catena determinato dalla formula:
Naturalmente, i cambiamenti relativi medi di base e a catena devono essere gli stessi e, confrontandoli con il valore del criterio 1, si trae una conclusione sulla natura del cambiamento nel fenomeno in media: crescita, declino o stabilità.
Sottraendo 1 dalla variazione relativa media di base o catena, il corrispondente tasso medio di variazione, dal cui segno si può giudicare anche la natura del cambiamento del fenomeno in esame, riflesso da questa serie di dinamiche.
Fluttuazioni stagionali e indici di stagionalità.
Le fluttuazioni stagionali sono fluttuazioni intra-annuali stabili.
Il principio di base della gestione per ottenere il massimo effetto è massimizzare il reddito e minimizzare i costi. Studiando le fluttuazioni stagionali, il problema dell'equazione massima viene risolto ad ogni livello dell'anno.
Quando si studiano le fluttuazioni stagionali, vengono risolti due problemi correlati:
1. Individuazione delle specificità dello sviluppo del fenomeno nelle dinamiche intra-annuali;
2. Misurare le fluttuazioni stagionali con la costruzione di un modello di onde stagionali;
Per misurare la variazione stagionale, vengono solitamente contati i tacchini stagionali. In generale, sono determinati dal rapporto tra le equazioni iniziali della serie dinamica e le equazioni teoriche, che fungono da base di confronto.
Poiché le deviazioni casuali si sovrappongono alle fluttuazioni stagionali, viene calcolata la media degli indici di stagionalità per eliminarle.
In questo caso, per ciascun periodo del ciclo annuale, gli indicatori generalizzati vengono determinati sotto forma di indici medi stagionali:
Gli indici medi di fluttuazione stagionale sono esenti dall'influenza di deviazioni casuali della tendenza di sviluppo principale.
A seconda della natura del trend, la formula per l’indice di stagionalità media può assumere le seguenti forme:
1.Per serie di dinamiche intraannuali con una tendenza principale di sviluppo chiaramente espressa:
2. Per serie di dinamiche infrannuali in cui non si riscontra un trend crescente o decrescente o risulta insignificante:
Dov'è la media complessiva;
Metodi per analizzare il trend principale.
Lo sviluppo dei fenomeni nel tempo è influenzato da fattori di diversa natura e forza di influenza. Alcuni di essi sono di natura casuale, altri hanno un impatto quasi costante e formano una certa tendenza di sviluppo nella dinamica.
Un compito importante della statistica è identificare le dinamiche di tendenza in serie, liberate dall'influenza di vari fattori casuali. A questo scopo, le serie temporali vengono elaborate mediante metodi di ampliamento degli intervalli, media mobile e livellamento analitico, ecc.
Metodo di allargamento degli intervalli si basa sull’ampliamento degli intervalli temporali, che comprendono i livelli di una serie di dinamiche, cioè è la sostituzione dei dati relativi a periodi di tempo brevi con dati relativi a periodi più ampi. È particolarmente efficace quando i livelli iniziali della serie si riferiscono a brevi periodi di tempo. Ad esempio, le serie di indicatori relativi agli eventi giornalieri vengono sostituite da serie relative agli eventi settimanali, mensili, ecc. Questo mostrerà più chiaramente “asse di sviluppo del fenomeno”. La media, calcolata su intervalli più ampi, consente di individuare la direzione e la natura (accelerazione o rallentamento della crescita) del principale trend di sviluppo.
Metodo della media mobile simile al precedente, ma in questo caso i livelli effettivi sono sostituiti da livelli medi calcolati per intervalli allargati spostati sequenzialmente (scorrevoli) che coprono M livelli di serie.
Per esempio, se accettiamo m=3, quindi prima viene calcolata la media dei primi tre livelli della serie, quindi - dallo stesso numero di livelli, ma a partire dal secondo, quindi - a partire dal terzo, ecc. Pertanto, la media “scivola” lungo la serie dinamica, spostandosi di un termine. Calcolato da M membri, le medie mobili si riferiscono alla metà (centro) di ciascun intervallo.
Questo metodo elimina solo le fluttuazioni casuali. Se la serie presenta un'onda stagionale, essa persisterà anche dopo lo livellamento utilizzando il metodo della media mobile.
Allineamento analitico. Per eliminare le fluttuazioni casuali e identificare una tendenza, viene utilizzato il livellamento dei livelli delle serie utilizzando formule analitiche (o livellamento analitico). La sua essenza è quella di sostituire i livelli empirici (effettivi) con quelli teorici, che vengono calcolati utilizzando una certa equazione adottata come modello di tendenza matematico, dove i livelli teorici sono considerati in funzione del tempo: . In questo caso, ogni livello effettivo è considerato come la somma di due componenti: , dove è una componente sistematica ed espressa da una determinata equazione, ed è una variabile casuale che provoca fluttuazioni attorno al trend.
Il compito dell’allineamento analitico si riduce a quanto segue:
1. Determinazione, sulla base di dati reali, della tipologia di ipotetica funzione che può riflettere più adeguatamente il trend di sviluppo dell'indicatore oggetto di studio.
2. Trovare i parametri della funzione specificata (equazione) da dati empirici
3. Calcolo utilizzando l'equazione trovata dei livelli teorici (allineati).
La scelta di una particolare funzione viene effettuata, di regola, sulla base di una rappresentazione grafica di dati empirici.
I modelli sono equazioni di regressione, i cui parametri sono calcolati utilizzando il metodo dei minimi quadrati
Di seguito sono riportate le equazioni di regressione più comunemente utilizzate per allineare le serie temporali, indicando quali tendenze di sviluppo specifiche sono più adatte a riflettere.
Per trovare i parametri delle equazioni di cui sopra, esistono algoritmi speciali e programmi per computer. In particolare, per trovare i parametri di un'equazione di linea retta si può utilizzare il seguente algoritmo:

Se i periodi o istanti di tempo sono numerati in modo tale che St = 0, gli algoritmi di cui sopra saranno notevolmente semplificati e si trasformeranno in

I livelli allineati sul grafico si troveranno su una linea retta, che passa alla distanza più vicina dai livelli effettivi di questa serie dinamica. La somma dei quadrati delle deviazioni riflette l'influenza di fattori casuali.
Usandolo, calcoliamo l'errore medio (standard) dell'equazione:

Qui n è il numero di osservazioni e m è il numero di parametri nell'equazione (ne abbiamo due: b 1 e b 0).
La tendenza principale (tendenza) mostra come i fattori sistematici influenzano i livelli di una serie di dinamiche e la fluttuazione dei livelli attorno alla tendenza () serve come misura dell'influenza dei fattori residui.
Per valutare la qualità del modello di serie temporale utilizzato, viene utilizzato anche questo Test F di Fisher. È il rapporto tra due varianze, ovvero il rapporto della varianza causata dalla regressione, ovvero il fattore studiato, alla varianza causata da ragioni casuali, vale a dire dispersione residua:
![]()
In forma estesa, la formula per questo criterio può essere presentata come segue:
![]()
dove n è il numero di osservazioni, cioè numero di livelli di riga,
m è il numero di parametri nell'equazione, y è il livello effettivo della serie,
Livello riga allineata - livello riga centrale.
Un modello che ha più successo di altri potrebbe non essere sempre sufficientemente soddisfacente. Può essere riconosciuto come tale solo nel caso in cui il suo criterio F supera il limite critico noto. Questo limite viene stabilito utilizzando le tabelle di distribuzione F.
Essenza e classificazione degli indici.
In statistica, per indice si intende un indicatore relativo che caratterizza il cambiamento dell'entità di un fenomeno nel tempo, nello spazio o rispetto a qualsiasi standard.
L'elemento principale della relazione di indice è il valore indicizzato. Per valore indicizzato si intende il valore di una caratteristica di una popolazione statistica, il cui cambiamento è oggetto di studio.
Utilizzando gli indici, vengono risolti tre compiti principali:
1) valutazione dei cambiamenti in un fenomeno complesso;
2) determinare l'influenza di fattori individuali sui cambiamenti in un fenomeno complesso;
3) confronto dell'entità di un fenomeno con l'entità del periodo passato, con l'entità di un altro territorio, nonché con standard, piani e previsioni.
Gli indici sono classificati secondo 3 criteri:
2) in base al grado di copertura degli elementi della popolazione;
3) secondo modalità di calcolo degli indici generali.
Per contenuto quantità indicizzate, gli indici sono suddivisi in indici di indicatori quantitativi (di volume) e indici di indicatori qualitativi. Indici di indicatori quantitativi - indici del volume fisico dei prodotti industriali, volume fisico delle vendite, numero di dipendenti, ecc. Indici di indicatori qualitativi - indici di prezzi, costi, produttività del lavoro, salari medi, ecc.
In base al grado di copertura delle unità di popolazione, gli indici sono divisi in due classi: individuali e generali. Per caratterizzarli, introduciamo le seguenti convenzioni adottate nella pratica di utilizzo del metodo dell'indice:
Q- quantità (volume) di qualsiasi prodotto in termini fisici ; R- prezzo unitario; z- costo unitario di produzione; T— tempo impiegato per produrre un'unità di prodotto (intensità di lavoro) ; w- produzione di prodotti in termini di valore per unità di tempo; v- rendimento della produzione in termini fisici per unità di tempo; T— tempo totale impiegato o numero di dipendenti.
Per distinguere a quale periodo o oggetto appartengono le quantità indicizzate, è consuetudine porre i pedici in basso a destra del simbolo corrispondente. Quindi, ad esempio, negli indici dinamici, di regola, il pedice 1 viene utilizzato per i periodi da confrontare (corrente, reporting) e per i periodi con cui viene effettuato il confronto,
Indici individuali servire a caratterizzare i cambiamenti nei singoli elementi di un fenomeno complesso (ad esempio, un cambiamento nel volume di produzione di un tipo di prodotto). Rappresentano valori relativi di dinamica, adempimento di obblighi, confronto di valori indicizzati.
Viene determinato l'indice individuale del volume fisico dei prodotti
Da un punto di vista analitico, gli indici di dinamica individuali forniti sono simili ai coefficienti (tassi) di crescita e caratterizzano la variazione del valore indicizzato nel periodo corrente rispetto al periodo base, cioè mostrano quante volte esso è aumentato (diminuito) o quale percentuale è la crescita (diminuzione). I valori dell'indice sono espressi in coefficienti o percentuali.
Indice generale (composito). riflette i cambiamenti in tutti gli elementi di un fenomeno complesso.
Indice aggregatoè la forma base di un indice. Si chiama aggregato perché il suo numeratore e denominatore sono un insieme di “aggregati”
Indici medi, loro definizione.
Oltre agli indici aggregati, nelle statistiche viene utilizzata un'altra forma: gli indici medi ponderati. Al loro calcolo si ricorre quando le informazioni disponibili non consentono di calcolare l'indice generale aggregato. Pertanto, se non sono disponibili dati sui prezzi, ma sono disponibili informazioni sul costo dei prodotti nel periodo corrente e sono noti gli indici dei prezzi individuali per ciascun prodotto, l'indice generale dei prezzi non può essere determinato come aggregato, ma è possibile calcolarlo come media di quelli individuali. Allo stesso modo, se non si conoscono le quantità dei singoli tipi di prodotti prodotti, ma si conoscono gli indici individuali e il costo di produzione del periodo base, allora l'indice generale del volume fisico di produzione può essere determinato come media ponderata valore.
Indice medio - Questo un indice calcolato come media dei singoli indici. Un indice aggregato è la forma base di un indice generale, quindi l'indice medio deve essere identico all'indice aggregato. Quando si calcolano gli indici medi, vengono utilizzate due forme di media: aritmetica e armonica.
L'indice medio aritmetico è identico all'indice aggregato se i pesi dei singoli indici sono i termini del denominatore dell'indice aggregato. Solo in questo caso il valore dell'indice calcolato con la formula della media aritmetica sarà pari all'indice aggregato.
Secondo l’indagine campionaria, i depositanti sono stati raggruppati in base all’entità del loro deposito presso la Sberbank della città:
Definire:
1) ambito di variazione;
2) dimensione media del deposito;
3) deviazione lineare media;
4) dispersione;
5) deviazione standard;
6) coefficiente di variazione dei contributi.
Soluzione:
Questa serie di distribuzione contiene intervalli aperti. In tali serie, si assume convenzionalmente che il valore dell'intervallo del primo gruppo sia uguale al valore dell'intervallo del successivo, e il valore dell'intervallo dell'ultimo gruppo sia uguale al valore dell'intervallo del precedente.
Il valore dell'intervallo del secondo gruppo è pari a 200, quindi anche il valore del primo gruppo è pari a 200. Il valore dell'intervallo del penultimo gruppo è pari a 200, il che significa che anche l'ultimo intervallo sarà hanno un valore di 200.
1) Definiamo l'intervallo di variazione come la differenza tra il valore più grande e quello più piccolo dell'attributo:
L'intervallo di variazione dell'importo del deposito è di 1000 rubli.
2) L'entità media del contributo sarà determinata utilizzando la formula della media aritmetica ponderata.
Determiniamo innanzitutto il valore discreto dell'attributo in ciascun intervallo. Per fare ciò, utilizzando la semplice formula della media aritmetica, troviamo i punti medi degli intervalli.
Il valore medio del primo intervallo sarà:

il secondo - 500, ecc.
Inseriamo i risultati del calcolo nella tabella:
| Importo del deposito, strofinare. | Numero di depositanti, f | Metà dell'intervallo, x | xf |
|---|---|---|---|
| 200-400 | 32 | 300 | 9600 |
| 400-600 | 56 | 500 | 28000 |
| 600-800 | 120 | 700 | 84000 |
| 800-1000 | 104 | 900 | 93600 |
| 1000-1200 | 88 | 1100 | 96800 |
| Totale | 400 | - | 312000 |
Il deposito medio nella Sberbank della città sarà di 780 rubli:
3) La deviazione lineare media è la media aritmetica delle deviazioni assolute dei singoli valori di una caratteristica dalla media complessiva:

La procedura per calcolare la deviazione lineare media nella serie di distribuzione degli intervalli è la seguente:
1. Si calcola la media aritmetica ponderata, come indicato al comma 2).
2. Vengono determinate le deviazioni assolute dalla media:
3. Le deviazioni risultanti vengono moltiplicate per le frequenze:
4. Trova la somma delle deviazioni ponderate senza tenere conto del segno:
5. La somma delle deviazioni ponderate è divisa per la somma delle frequenze:
È conveniente utilizzare la tabella dei dati di calcolo:
| Importo del deposito, strofinare. | Numero di depositanti, f | Metà dell'intervallo, x | |||
|---|---|---|---|---|---|
| 200-400 | 32 | 300 | -480 | 480 | 15360 |
| 400-600 | 56 | 500 | -280 | 280 | 15680 |
| 600-800 | 120 | 700 | -80 | 80 | 9600 |
| 800-1000 | 104 | 900 | 120 | 120 | 12480 |
| 1000-1200 | 88 | 1100 | 320 | 320 | 28160 |
| Totale | 400 | - | - | - | 81280 |

La deviazione lineare media dell'entità del deposito dei clienti Sberbank è di 203,2 rubli.
4) La dispersione è la media aritmetica delle deviazioni al quadrato di ciascun valore di attributo dalla media aritmetica.
Il calcolo della varianza nelle serie di distribuzione di intervalli viene effettuato utilizzando la formula:

La procedura per calcolare la varianza in questo caso è la seguente:
1. Determinare la media aritmetica ponderata, come indicato al paragrafo 2).
2. Trova le deviazioni dalla media:
3. Eleva al quadrato la deviazione di ciascuna opzione dalla media:
4. Moltiplicare i quadrati delle deviazioni per i pesi (frequenze):
![]()
5. Riassumi i prodotti risultanti:
![]()
6. L'importo risultante viene diviso per la somma dei pesi (frequenze):

Mettiamo i calcoli in una tabella:
| Importo del deposito, strofinare. | Numero di depositanti, f | Metà dell'intervallo, x | |||
|---|---|---|---|---|---|
| 200-400 | 32 | 300 | -480 | 230400 | 7372800 |
| 400-600 | 56 | 500 | -280 | 78400 | 4390400 |
| 600-800 | 120 | 700 | -80 | 6400 | 768000 |
| 800-1000 | 104 | 900 | 120 | 14400 | 1497600 |
| 1000-1200 | 88 | 1100 | 320 | 102400 | 9011200 |
| Totale | 400 | - | - | - | 23040000 |
Deviazione standard
La caratteristica più perfetta della variazione è la deviazione quadratica media, chiamata standard (o deviazione standard). Deviazione standard() è uguale alla radice quadrata della deviazione quadrata media dei singoli valori dell'attributo dalla media aritmetica:
La deviazione standard è semplice:


La deviazione standard ponderata viene applicata ai dati raggruppati:

Il seguente rapporto si verifica tra il quadrato medio e le deviazioni lineari medie in condizioni di distribuzione normale: ~ 1,25.
La deviazione standard, essendo la principale misura assoluta di variazione, viene utilizzata per determinare i valori ordinati di una curva di distribuzione normale, nei calcoli relativi all'organizzazione dell'osservazione del campione e per stabilire l'accuratezza delle caratteristiche del campione, nonché nella valutazione della limiti di variazione di una caratteristica in una popolazione omogenea.
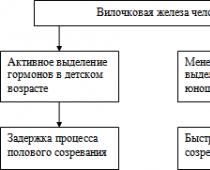
18. Varianza, sue tipologie, deviazione standard.
Varianza di una variabile casuale- una misura della diffusione di una determinata variabile casuale, ovvero la sua deviazione dall'aspettativa matematica. Nelle statistiche viene spesso utilizzata la notazione o . Di solito viene chiamata la radice quadrata della varianza deviazione standard, deviazione standard o diffusione standard.
Varianza totale (σ2) misura la variazione di un tratto nel suo complesso sotto l'influenza di tutti i fattori che hanno causato tale variazione. Allo stesso tempo, grazie al metodo del raggruppamento, è possibile identificare e misurare la variazione dovuta alle caratteristiche del raggruppamento e la variazione derivante dall'influenza di fattori non contabilizzati.
Varianza intergruppo (σ 2 m.gr) caratterizza la variazione sistematica, ad es. differenze nel valore del tratto studiato che sorgono sotto l'influenza del tratto, il fattore che costituisce la base del gruppo.
Deviazione standard(sinonimi: deviazione standard, deviazione standard, deviazione quadrata; termini correlati: deviazione standard, diffusione standard) - nella teoria e nella statistica della probabilità, l'indicatore più comune della dispersione dei valori di una variabile casuale rispetto alla sua aspettativa matematica. Con matrici limitate di campioni di valori, invece dell'aspettativa matematica, viene utilizzata la media aritmetica dell'insieme di campioni.
La deviazione standard viene misurata in unità di misura della variabile casuale stessa e viene utilizzata quando si calcola l'errore standard della media aritmetica, quando si costruiscono intervalli di confidenza, quando si testano statisticamente ipotesi, quando si misura la relazione lineare tra variabili casuali. Definito come la radice quadrata della varianza di una variabile casuale.
Deviazione standard:

Deviazione standard(stima della deviazione standard di una variabile casuale X rispetto alla sua aspettativa matematica basata su una stima imparziale della sua varianza):

dov'è la dispersione; - io elemento della selezione; - misura di prova; - media aritmetica del campione:
![]()
Va notato che entrambe le stime sono distorte. Nel caso generale, è impossibile costruire una stima imparziale. In questo caso, la stima basata sulla stima imparziale della varianza è coerente.
19. Essenza, ambito e procedura per la determinazione della moda e della mediana.
Oltre alle medie di potenza in statistica, per la caratterizzazione relativa del valore di una caratteristica variabile e la struttura interna delle serie di distribuzione, vengono utilizzate le medie strutturali, rappresentate principalmente da moda e mediana.
Moda- Questa è la variante più comune della serie. La moda viene utilizzata, ad esempio, per determinare la taglia dei vestiti e delle scarpe più richieste dai clienti. La modalità per una serie discreta è la variante con la frequenza più alta. Quando si calcola la modalità per una serie di variazioni di intervallo, è estremamente importante determinare prima l'intervallo modale (per frequenza massima), quindi - il valore del valore modale dell'attributo utilizzando la formula:

§ - significato della moda
§ - limite inferiore dell'intervallo modale
§ - valore dell'intervallo
§ - frequenza dell'intervallo modale
§ - frequenza dell'intervallo che precede il modale
§ - frequenza dell'intervallo successivo al modale
Mediano - questo valore dell'attributo, ĸᴏᴛᴏᴩᴏᴇ sta alla base della serie classificata e divide questa serie in due parti uguali in numero.
Per determinare la mediana in una serie discreta se le frequenze sono disponibili, calcolare prima la metà della somma delle frequenze, quindi determinare quale valore della variante ricade su di essa. (Se la serie ordinata contiene un numero dispari di caratteristiche, il numero mediano viene calcolato utilizzando la formula:
M e = (n (numero di caratteristiche in totale) + 1)/2,
nel caso di un numero pari di caratteristiche, la mediana sarà pari alla media delle due caratteristiche al centro della riga).
Quando si calcola la mediana per le serie a variazione di intervallo Innanzitutto, determinare l'intervallo mediano entro il quale si trova la mediana, quindi determinare il valore della mediana utilizzando la formula:

§ - la mediana richiesta
§ - limite inferiore dell'intervallo che contiene la mediana
§ - valore dell'intervallo
§ - somma delle frequenze o numero dei termini della serie
§ - la somma delle frequenze accumulate degli intervalli precedenti la mediana
§ - frequenza dell'intervallo mediano
Esempio. Trova la moda e la mediana.
Soluzione: In questo esempio, l'intervallo modale rientra nella fascia di età 25-30 anni, poiché questo intervallo ha la frequenza più alta (1054).
Calcoliamo l'entità della modalità:
Ciò significa che l’età modale degli studenti è di 27 anni.
Calcoliamo la mediana. L'intervallo mediano è nella fascia di età 25-30 anni, poiché all'interno di questo intervallo esiste un'opzione͵ che divide la popolazione in due parti uguali (Σf i /2 = 3462/2 = 1731). Successivamente, sostituiamo i dati numerici necessari nella formula e otteniamo il valore mediano:

Ciò significa che la metà degli studenti ha meno di 27,4 anni e l'altra metà ha più di 27,4 anni.
Oltre alla moda e alla mediana, vengono utilizzati indicatori come i quartili, che dividono la serie classificata in 4 parti uguali, i decili - 10 parti e i percentili - in 100 parti.
20. Il concetto di osservazione del campione e la sua portata.
Osservazione selettiva si applica quando si utilizza la sorveglianza continua fisicamente impossibile a causa di una grande quantità di dati o non economicamente fattibile. L'impossibilità fisica si verifica, ad esempio, quando si studiano i flussi di passeggeri, i prezzi di mercato e i bilanci familiari. L'inopportunità economica si verifica quando si valuta la qualità dei beni associati alla loro distruzione, ad esempio assaggiando, testando la resistenza dei mattoni, ecc.
Le unità statistiche selezionate per l'osservazione sono popolazione campione O campione, e il loro intero assortimento - popolazione generale(GS). In cui numero di unità nel campione denota N, e nell'intero GS - N. Atteggiamento n/N solitamente chiamato dimensione relativa O condivisione del campione.
La qualità dei risultati dell'osservazione del campione dipende da rappresentatività del campione, cioè da quanto sia rappresentativo nel GS. Per garantire la rappresentatività del campione, è estremamente importante conformarsi principio della selezione casuale delle unità, che presuppone che l'inclusione di un'unità HS nel campione non possa essere influenzata da alcun altro fattore se non dal caso.
Esiste 4 modi di selezione casuale campionare:
- In realtà casuale selezione o “metodo del lotto”, in cui vengono assegnati valori statistici numeri seriali, registrati su determinati oggetti (ad esempio, botti), che vengono poi mescolati in un contenitore (ad esempio, in una borsa) e selezionati in modo casuale. In pratica, questo metodo viene eseguito utilizzando un generatore di numeri casuali o tabelle matematiche di numeri casuali.
- Meccanico selezione in base alla quale ciascuno ( N/n)-esimo valore della popolazione generale. Ad esempio, se contiene 100.000 valori ed è necessario selezionarne 1.000, nel campione verrà incluso ogni 100.000/1.000 = 100esimo valore. Inoltre, se non sono classificati, il primo verrà selezionato a caso tra i primi cento e il numero degli altri sarà cento più alto. Ad esempio, se la prima unità fosse la n. 19, la successiva dovrebbe essere la n. 119, poi la n. 219, poi la n. 319, ecc. Se le unità di popolazione vengono classificate, viene selezionato per primo il n. 50, poi il n. 150, poi il n. 250 e così via.
- Viene eseguita la selezione di valori da un array di dati eterogeneo stratificato metodo (stratificato), quando la popolazione viene prima divisa in gruppi omogenei ai quali viene applicata la selezione casuale o meccanica.
- Un metodo di campionamento speciale è seriale selezione, in cui selezionano casualmente o meccanicamente non valori individuali, ma le loro serie (sequenze da un numero a un numero di seguito), all'interno delle quali viene effettuata l'osservazione continua.
Dipende anche dalla qualità delle osservazioni del campione tipo di campione: ripetuto O irripetibile. A riselezione I valori statistici o le loro serie inclusi nel campione vengono restituiti alla popolazione generale dopo l'uso, avendo la possibilità di essere inclusi in un nuovo campione. Inoltre, tutti i valori della popolazione generale hanno la stessa probabilità di inclusione nel campione. Selezione infinita significa che i valori statistici o le loro serie inclusi nel campione non ritornano alla popolazione generale dopo l’uso, e quindi per i restanti valori di quest’ultimo aumenta la probabilità di essere inclusi nel campione successivo.
Il campionamento non ripetitivo fornisce risultati più accurati e pertanto viene utilizzato più spesso. Ma ci sono situazioni in cui non può essere applicato (studio dei flussi di passeggeri, della domanda dei consumatori, ecc.) e quindi viene effettuata una selezione ripetuta.
21. Errore massimo di campionamento nell'osservazione, errore medio di campionamento, procedura per il loro calcolo.
Consideriamo in dettaglio i metodi sopra elencati per formare una popolazione campione e gli errori di rappresentatività che ne derivano. Giustamente casuale il campionamento si basa sulla selezione casuale di unità dalla popolazione senza elementi sistematici. Tecnicamente, la selezione casuale effettiva viene effettuata mediante estrazione a sorte (ad esempio, lotterie) o utilizzando una tabella di numeri casuali.
La selezione casuale corretta “nella sua forma pura” è usata raramente nella pratica dell’osservazione selettiva, ma è quella iniziale tra gli altri tipi di selezione; implementa i principi di base dell’osservazione selettiva. Consideriamo alcune domande sulla teoria del metodo di campionamento e sulla formula dell'errore per un campione casuale semplice.
Distorsione del campionamento- ϶ᴛᴏ la differenza tra il valore del parametro nella popolazione generale e il suo valore calcolato dai risultati dell'osservazione del campione. È importante notare che per la caratteristica quantitativa media l'errore di campionamento è determinato da
L'indicatore è solitamente chiamato errore massimo di campionamento. La media campionaria è una variabile casuale che può assumere valori diversi a seconda di quali unità sono incluse nel campione. Pertanto anche gli errori di campionamento sono variabili casuali e possono assumere valori diversi. Per questo motivo viene determinata la media dei possibili errori: errore medio di campionamento, che dipende da:
· dimensione del campione: maggiore è il numero, minore è l'errore medio;
· il grado di cambiamento della caratteristica studiata: minore è la variazione della caratteristica, e, di conseguenza, la dispersione, minore è l'errore medio di campionamento.
A riselezione casuale viene calcolato l'errore medio. In pratica, la varianza generale non è nota esattamente, ma nella teoria della probabilità è stato dimostrato ![]() . Poiché il valore di n sufficientemente grande è vicino a 1, possiamo supporre che . Successivamente si dovrebbe calcolare l'errore medio di campionamento: . Ma nei casi di campione piccolo (con n<30) коэффициент крайне важно учитывать, и среднюю ошибку малой выборки рассчитывать по формуле
. Poiché il valore di n sufficientemente grande è vicino a 1, possiamo supporre che . Successivamente si dovrebbe calcolare l'errore medio di campionamento: . Ma nei casi di campione piccolo (con n<30) коэффициент крайне важно учитывать, и среднюю ошибку малой выборки рассчитывать по формуле  .
.
A campionamento casuale non ripetitivo le formule fornite vengono regolate dal valore . Allora l’errore medio di campionamento non ripetitivo è:  E
E  . Perché è sempre inferiore a , allora il moltiplicatore () è sempre inferiore a 1. Ciò significa che l'errore medio con la selezione ripetuta è sempre inferiore rispetto a quello con la selezione ripetuta. Campionamento meccanico si utilizza quando la popolazione generale è ordinata in qualche modo (ad esempio, elenchi di elettori in ordine alfabetico, numeri di telefono, numeri di casa e di appartamento). La selezione delle unità viene effettuata ad un certo intervallo, che è uguale al valore inverso della percentuale di campionamento. Quindi, con un campione del 2%, viene selezionata ogni 50 unità = 1/0,02, con un campione del 5%, ogni 1/0,05 = 20 unità della popolazione generale.
. Perché è sempre inferiore a , allora il moltiplicatore () è sempre inferiore a 1. Ciò significa che l'errore medio con la selezione ripetuta è sempre inferiore rispetto a quello con la selezione ripetuta. Campionamento meccanico si utilizza quando la popolazione generale è ordinata in qualche modo (ad esempio, elenchi di elettori in ordine alfabetico, numeri di telefono, numeri di casa e di appartamento). La selezione delle unità viene effettuata ad un certo intervallo, che è uguale al valore inverso della percentuale di campionamento. Quindi, con un campione del 2%, viene selezionata ogni 50 unità = 1/0,02, con un campione del 5%, ogni 1/0,05 = 20 unità della popolazione generale.
Il punto di riferimento viene selezionato in diversi modi: in modo casuale, dalla metà dell'intervallo, con una modifica del punto di riferimento. La cosa principale è evitare errori sistematici. Ad esempio, con un campione del 5%, se la prima unità è la 13a, le successive sono 33, 53, 73, ecc.
In termini di accuratezza, la selezione meccanica è vicina al campionamento casuale effettivo. Per questo motivo, per determinare l'errore medio del campionamento meccanico, vengono utilizzate apposite formule di selezione casuale.
A selezione tipica la popolazione oggetto di indagine viene preliminarmente suddivisa in gruppi omogenei e simili. Ad esempio, quando si esaminano le imprese, si tratta di industrie, sottosettori; quando si studia la popolazione, si tratta di regioni, gruppi sociali o di età. Successivamente, viene effettuata una selezione indipendente da ciascun gruppo in modo meccanico o puramente casuale.
Il campionamento tipico produce risultati più accurati rispetto ad altri metodi. La tipizzazione della popolazione generale garantisce che ciascun gruppo tipologico sia rappresentato nel campione, il che rende possibile eliminare l'influenza della varianza intergruppo sull'errore medio di campionamento. Pertanto, quando si trova l'errore di un campione tipico secondo la regola della somma delle varianze (), è estremamente importante tenere conto solo della media delle varianze del gruppo. Quindi l'errore medio di campionamento: con campionamento ripetuto, con campionamento non ripetitivo  , Dove
, Dove  – la media delle varianze intragruppo del campione.
– la media delle varianze intragruppo del campione.
Selezione seriale (o nido). utilizzato quando la popolazione viene suddivisa in serie o gruppi prima dell'inizio dell'indagine campionaria. Queste serie includono il confezionamento di prodotti finiti, gruppi di studenti e brigate. Le serie da esaminare vengono selezionate meccanicamente o in modo puramente casuale e all'interno della serie viene effettuato un esame continuo delle unità. Per questo motivo, l’errore medio di campionamento dipende solo dalla varianza intergruppo (tra serie), che si calcola utilizzando la formula:  dove r è il numero di serie selezionate; – media della i-esima serie. Si calcola l'errore medio del campionamento seriale: con campionamento ripetuto, con campionamento non ripetitivo
dove r è il numero di serie selezionate; – media della i-esima serie. Si calcola l'errore medio del campionamento seriale: con campionamento ripetuto, con campionamento non ripetitivo  , dove R è il numero totale di serie. Combinato la selezione è una combinazione dei metodi di selezione considerati.
, dove R è il numero totale di serie. Combinato la selezione è una combinazione dei metodi di selezione considerati.
L'errore medio di campionamento per qualsiasi metodo di campionamento dipende principalmente dalla dimensione assoluta del campione e, in misura minore, dalla percentuale del campione. Supponiamo che 225 osservazioni vengano effettuate nel primo caso su una popolazione di 4.500 unità e nel secondo su una popolazione di 225.000 unità. Le varianze in entrambi i casi sono pari a 25. Quindi nel primo caso, con una selezione del 5%, l'errore campionario sarà:  Nel secondo caso, con selezione 0,1%, sarà pari a:
Nel secondo caso, con selezione 0,1%, sarà pari a:
 Tuttavia, quando la percentuale di campionamento è stata ridotta di 50 volte, l’errore di campionamento è leggermente aumentato, poiché la dimensione del campione non è cambiata. Supponiamo che la dimensione del campione venga aumentata a 625 osservazioni. In questo caso l’errore di campionamento è:
Tuttavia, quando la percentuale di campionamento è stata ridotta di 50 volte, l’errore di campionamento è leggermente aumentato, poiché la dimensione del campione non è cambiata. Supponiamo che la dimensione del campione venga aumentata a 625 osservazioni. In questo caso l’errore di campionamento è:  Aumentando il campione di 2,8 volte con la stessa dimensione della popolazione si riduce la dimensione dell’errore di campionamento di oltre 1,6 volte.
Aumentando il campione di 2,8 volte con la stessa dimensione della popolazione si riduce la dimensione dell’errore di campionamento di oltre 1,6 volte.
22.Metodi e metodi per formare una popolazione campione.
Nelle statistiche vengono utilizzati vari metodi per formare popolazioni campione, che sono determinati dagli obiettivi dello studio e dipendono dalle specificità dell'oggetto di studio.
La condizione principale per condurre un'indagine campionaria è quella di evitare il verificarsi di errori sistematici derivanti dalla violazione del principio di pari opportunità per ciascuna unità della popolazione generale da includere nel campione. La prevenzione degli errori sistematici si ottiene attraverso l'uso di metodi scientificamente fondati per formare una popolazione campione.
Esistono i seguenti metodi per selezionare le unità dalla popolazione generale: 1) selezione individuale: vengono selezionate singole unità per il campione; 2) selezione del gruppo - il campione comprende gruppi qualitativamente omogenei o serie di unità oggetto di studio; 3) la selezione combinata è una combinazione di selezione individuale e di gruppo. I metodi di selezione sono determinati dalle regole per formare una popolazione campione.
Il campione dovrebbe essere:
- effettivamente casuale consiste nel fatto che la popolazione campione si forma come risultato della selezione casuale (non intenzionale) di singole unità dalla popolazione generale. In questo caso, il numero di unità selezionate nella popolazione campione viene solitamente determinato in base alla proporzione campionaria accettata. La proporzione campionaria è il rapporto tra il numero di unità nella popolazione campione n e il numero di unità nella popolazione generale N, ᴛ.ᴇ.
- meccanico consiste nel fatto che la selezione delle unità della popolazione campione viene effettuata a partire dalla popolazione generale, divisa in intervalli uguali (gruppi). In questo caso, la dimensione dell'intervallo nella popolazione è uguale al reciproco della quota campionaria. Quindi, con un campione del 2%, viene selezionata ogni 50a unità (1:0,02), con un campione del 5% ogni 20a unità (1:0,05), ecc. Tuttavia, secondo la proporzione di selezione accettata, la popolazione generale è, per così dire, divisa meccanicamente in gruppi uguali. Da ciascun gruppo viene selezionata solo un'unità per il campione.
- tipico – in cui la popolazione generale viene prima divisa in gruppi tipici omogenei. Successivamente, da ciascun gruppo tipico, viene utilizzato un campione puramente casuale o meccanico per selezionare individualmente le unità nella popolazione campione. Una caratteristica importante di un campione tipico è che fornisce risultati più accurati rispetto ad altri metodi di selezione delle unità nella popolazione campione;
- seriale- in cui la popolazione generale è divisa in gruppi di uguale dimensione - serie. Le serie vengono selezionate nella popolazione campione. All'interno della serie viene effettuata l'osservazione continua delle unità comprese nella serie;
- combinato- il campionamento dovrebbe avvenire in due fasi. In questo caso, la popolazione viene prima divisa in gruppi. Successivamente vengono selezionati i gruppi e, all'interno di questi ultimi, le singole unità.
In statistica si distinguono i seguenti metodi per selezionare le unità in una popolazione campione:
- singola fase campionamento - ogni unità selezionata viene immediatamente sottoposta a studio secondo un determinato criterio (campionamento casuale e seriale vero e proprio);
- multistadio campionamento: viene effettuata una selezione dalla popolazione generale dei singoli gruppi e le singole unità vengono selezionate dai gruppi (campionamento tipico con un metodo meccanico di selezione delle unità nella popolazione campione).
Inoltre, ci sono:
- riselezione- secondo lo schema della palla restituita. In questo caso ogni unità o serie inclusa nel campione viene restituita alla popolazione generale e quindi ha la possibilità di essere nuovamente inclusa nel campione;
- ripetere la selezione- secondo lo schema della palla non restituita. Ha risultati più accurati con la stessa dimensione del campione.
23. Determinazione della dimensione del campione estremamente importante (utilizzando la t-table di Student).
Uno dei principi scientifici della teoria del campionamento è garantire che venga selezionato un numero sufficiente di unità. Teoricamente, l'estrema importanza di osservare questo principio è presentata nelle dimostrazioni dei teoremi limite nella teoria della probabilità, che consentono di stabilire quale volume di unità dovrebbe essere selezionato dalla popolazione in modo che sia sufficiente e garantisca la rappresentatività del campione.
Una diminuzione dell'errore standard di campionamento, e quindi un aumento dell'accuratezza della stima, è sempre associata ad un aumento della dimensione del campione; pertanto, già nella fase di organizzazione di un'osservazione campionaria, è necessario decidere quale sia la dimensione della popolazione campione dovrebbe essere tale da garantire la necessaria accuratezza dei risultati dell'osservazione. Il calcolo del volume estremamente importante del campione viene costruito utilizzando formule derivate dalle formule per gli errori massimi di campionamento (A), corrispondenti ad un particolare tipo e metodo di selezione. Quindi, per una dimensione del campione ripetuto casuale (n) abbiamo:

L'essenza di questa formula è che con un campionamento casuale ripetuto di numeri estremamente importanti, la dimensione del campione è direttamente proporzionale al quadrato del coefficiente di confidenza (t2) e varianza della caratteristica variazionale (?2) ed è inversamente proporzionale al quadrato dell'errore massimo di campionamento (?2). In particolare, aumentando l’errore massimo di un fattore due, la dimensione del campione richiesto dovrebbe essere ridotta di un fattore quattro. Dei tre parametri, due (t e?) sono impostati dal ricercatore. Allo stesso tempo, il ricercatore, in base all'obiettivo
e i problemi di un’indagine campionaria devono risolvere la domanda: in quale combinazione quantitativa è meglio includere questi parametri per garantire l’opzione ottimale? In un caso, potrebbe essere più soddisfatto dell'affidabilità dei risultati ottenuti (t) che della misura dell'accuratezza (?), nell'altro - viceversa. È più difficile risolvere la questione relativa al valore dell'errore massimo di campionamento, poiché il ricercatore non dispone di questo indicatore nella fase di progettazione dell'osservazione del campione; quindi, in pratica, è consuetudine fissare il valore dell'errore massimo di campionamento , solitamente entro il 10% del livello medio previsto dell'attributo . La determinazione della media stimata può essere affrontata in diversi modi: utilizzando dati provenienti da indagini precedenti simili, oppure utilizzando dati provenienti dal quadro di campionamento e conducendo un piccolo campione pilota.
La cosa più difficile da stabilire quando si progetta un'osservazione campionaria è il terzo parametro nella formula (5.2): la varianza della popolazione campione. In questo caso, è estremamente importante utilizzare tutte le informazioni a disposizione del ricercatore, ottenute in precedenti indagini simili e pilota.
La questione della determinazione della dimensione campionaria estremamente importante diventa più complicata se l'indagine campionaria prevede lo studio di diverse caratteristiche delle unità campionarie. In questo caso, i livelli medi di ciascuna caratteristica e la loro variazione, di regola, sono diversi e, a questo proposito, decidere quale varianza di quale caratteristica dare la preferenza è possibile solo tenendo conto dello scopo e degli obiettivi del sondaggio.
Quando si progetta un'osservazione del campione, si assume un valore predeterminato dell'errore di campionamento ammissibile in conformità con gli obiettivi di un particolare studio e la probabilità di conclusioni basate sui risultati dell'osservazione.
In generale, la formula dell’errore massimo della media campionaria permette di determinare:
‣‣‣ l'entità delle possibili deviazioni degli indicatori della popolazione generale dagli indicatori della popolazione campione;
‣‣‣ la dimensione del campione richiesta per garantire la precisione richiesta, alla quale i limiti di possibile errore non superano un determinato valore specificato;
‣‣‣ la probabilità che l'errore nel campione abbia un limite specificato.
Distribuzione degli studenti nella teoria della probabilità, è una famiglia ad un parametro di distribuzioni assolutamente continue.
24. Serie dinamica (intervallo, momento), serie dinamica di chiusura.
Serie dinamica- questi sono i valori degli indicatori statistici presentati in una determinata sequenza cronologica.
Ogni serie temporale contiene due componenti:
1) indicatori di periodi di tempo(anni, trimestri, mesi, giorni o date);
2) indicatori che caratterizzano l'oggetto in studio per periodi di tempo o nelle date corrispondenti, che vengono chiamati livelli di serie.
I livelli delle serie sono espressi sia in valori assoluti che medi o relativi. Tenendo conto della dipendenza dalla natura degli indicatori, vengono costruite serie dinamiche di valori assoluti, relativi e medi. Le serie dinamiche di valori relativi e medi sono costruite sulla base di serie derivate di valori assoluti. Esistono serie di dinamiche di intervalli e di momenti.
Serie di intervalli dinamici contiene i valori degli indicatori per determinati periodi di tempo. In una serie di intervalli è possibile sommare i livelli per ottenere il volume del fenomeno su un periodo più lungo, ovvero i cosiddetti totali accumulati.
Serie di momenti dinamici riflette i valori degli indicatori in un certo momento (data dell'ora). Nelle serie momentanee, il ricercatore può essere interessato solo alla differenza nei fenomeni che riflette il cambiamento nel livello della serie tra determinate date, poiché la somma dei livelli qui non ha contenuto reale. I totali cumulativi non vengono calcolati qui.
La condizione più importante per la corretta costruzione delle serie temporali è comparabilità dei livelli delle serie appartenenti a periodi diversi. I livelli devono essere presentati in quantità omogenee e deve esserci pari completezza di copertura delle diverse parti del fenomeno.
Per evitare distorsioni della dinamica reale, nella ricerca statistica si effettuano calcoli preliminari (a chiusura delle serie dinamiche), che precedono l'analisi statistica delle serie storiche. Sotto chiudendo la serie delle dinamicheÈ generalmente accettato comprendere la combinazione in una serie di due o più serie, i cui livelli sono calcolati utilizzando metodologie diverse o non corrispondono ai confini territoriali, ecc. La chiusura delle serie dinamiche può anche implicare il portare i livelli assoluti delle serie dinamiche su una base comune, il che neutralizza l'incomparabilità dei livelli delle serie dinamiche.
25. Il concetto di comparabilità delle serie dinamiche, dei coefficienti, della crescita e dei tassi di crescita.
Serie dinamica- si tratta di una serie di indicatori statistici che caratterizzano l'evoluzione dei fenomeni naturali e sociali nel tempo. Le raccolte statistiche pubblicate dal Comitato statale di statistica della Russia contengono un gran numero di serie dinamiche in forma tabellare. Le serie dinamiche consentono di identificare modelli di sviluppo dei fenomeni studiati.
Le serie dinamiche contengono due tipi di indicatori. Indicatori temporali(anni, trimestri, mesi, ecc.) o punti temporali (all'inizio dell'anno, all'inizio di ogni mese, ecc.). Indicatori di livello di riga. Gli indicatori dei livelli delle serie dinamiche possono essere espressi in valori assoluti (produzione del prodotto in tonnellate o rubli), valori relativi (quota della popolazione urbana in %) e valori medi (salario medio dei lavoratori del settore per anno , eccetera.). In forma tabellare, una serie temporale contiene due colonne o due righe.
La corretta costruzione delle serie storiche richiede il rispetto di una serie di requisiti:
- tutti gli indicatori di una serie di dinamiche devono essere scientificamente fondati e affidabili;
- gli indicatori di una serie di dinamiche devono essere confrontabili nel tempo, ᴛ.ᴇ. devono essere calcolati per gli stessi periodi di tempo o nelle stesse date;
- gli indicatori di alcune dinamiche devono essere comparabili sul territorio;
- gli indicatori di una serie di dinamiche devono essere confrontabili nel contenuto, ᴛ.ᴇ. calcolato secondo un'unica metodologia, allo stesso modo;
- gli indicatori di una serie di dinamiche dovrebbero essere comparabili in tutta la gamma di aziende agricole prese in considerazione. Tutti gli indicatori di una serie di dinamiche devono essere espressi nelle stesse unità di misura.
Gli indicatori statistici possono caratterizzare sia i risultati del processo studiato in un periodo di tempo, sia lo stato del fenomeno studiato in un determinato momento, ᴛ.ᴇ. gli indicatori possono essere intervallati (periodici) e momentanei. Di conseguenza, inizialmente le serie dinamiche sono intervalli o momenti. Le serie dinamiche dei momenti, a loro volta, presentano intervalli di tempo uguali e disuguali.
La serie dinamica originaria può essere trasformata in una serie di valori medi e in una serie di valori relativi (a catena e di base). Tali serie temporali sono chiamate serie temporali derivate.
La metodologia per calcolare il livello medio nelle serie dinamiche è diversa, a seconda del tipo di serie dinamica. Usando esempi, considereremo i tipi di serie dinamiche e le formule per il calcolo del livello medio.
Aumenti assoluti (Δy) mostrano di quante unità è cambiato il livello successivo della serie rispetto a quello precedente (gr. 3. - incrementi assoluti di catena) o rispetto al livello iniziale (gr. 4. - incrementi assoluti di base). Le formule di calcolo possono essere scritte come segue:

Quando i valori assoluti della serie diminuiscono, si avrà rispettivamente una “diminuzione” o una “diminuzione”.
Gli indicatori di crescita assoluta indicano che, ad esempio, nel 1998. la produzione del prodotto “A” è aumentata rispetto al 1997. di 4mila tonnellate, e rispetto al 1994 ᴦ. - per 34mila tonnellate; per gli altri anni vedi tabella. 11,5 gr.
Pubblicato su rif.rf
3 e 4.
Tasso di crescita mostra quante volte il livello della serie è cambiato rispetto a quello precedente (gr. 5 - coefficienti di crescita o declino a catena) o rispetto al livello iniziale (gr. 6 - coefficienti base di crescita o declino). Le formule di calcolo possono essere scritte come segue:

Tassi di crescita mostrare in quale percentuale è il livello successivo della serie rispetto a quello precedente (colonna 7 - tassi di crescita a catena) o rispetto al livello iniziale (gr. 8 - tassi di crescita di base). Le formule di calcolo possono essere scritte come segue:

Così, ad esempio, nel 1997. volume di produzione del prodotto "A" rispetto al 1996 ᴦ. ammontavano al 105,5% (
Tasso di crescita mostrare in quale percentuale il livello del periodo di riferimento è aumentato rispetto a quello precedente (colonna 9 - tassi di crescita a catena) o rispetto al livello iniziale (colonna 10 - tassi di crescita di base). Le formule di calcolo possono essere scritte come segue:
T pr = T r - 100% o T pr = crescita assoluta/livello del periodo precedente * 100%
Quindi, ad esempio, nel 1996. rispetto al 1995 ᴦ. Il prodotto "A" è stato prodotto in più del 3,8% (103,8% - 100%) o (8:210) x 100% e rispetto al 1994 ᴦ. - del 9% (109% - 100%).
Se i livelli assoluti della serie diminuiscono, il tasso sarà inferiore al 100% e, di conseguenza, ci sarà un tasso di diminuzione (il tasso di aumento con un segno meno).
In valore assoluto aumento dell'1%.(gr.
Pubblicato su rif.rf
11) mostra quante unità devono essere prodotte in un dato periodo affinché il livello del periodo precedente aumenti dell'1%. Nel nostro esempio, nel 1995 ᴦ. era necessario produrne 2.0mila tonnellate e nel 1998 ᴦ. - 2,3 mila tonnellate, ᴛ.ᴇ. molto più grande.
Il valore assoluto della crescita dell’1% può essere determinato in due modi:
§ il livello del periodo precedente diviso 100;
§ gli incrementi assoluti della catena sono divisi per i corrispondenti tassi di crescita della catena.
Valore assoluto di aumento dell'1% = 
Nelle dinamiche, soprattutto di lungo periodo, è importante un'analisi congiunta del tasso di crescita con il contenuto di ogni aumento o diminuzione percentuale.
Si noti che la metodologia considerata per l'analisi delle serie temporali è applicabile sia alle serie temporali, i cui livelli sono espressi in valori assoluti (t, migliaia di rubli, numero di dipendenti, ecc.), sia alle serie temporali, i cui livelli sono espressi in indicatori relativi (% di difetti, % contenuto in ceneri del carbone, ecc.) o in valori medi (resa media in c/ha, salario medio, ecc.).
Insieme agli indicatori analitici considerati, calcolati per ciascun anno rispetto al livello precedente o iniziale, quando si analizzano le serie dinamiche, è estremamente importante calcolare gli indicatori analitici medi per il periodo: il livello medio della serie, la media annua assoluta aumento (diminuzione) e il tasso di crescita medio annuo e il tasso di crescita .
I metodi per calcolare il livello medio di una serie di dinamiche sono stati discussi sopra. Nella serie dinamica degli intervalli che stiamo considerando, il livello medio della serie viene calcolato utilizzando la semplice formula della media aritmetica:
Volume di produzione medio annuo del prodotto per il periodo 1994-1998. ammontavano a 218,4 mila tonnellate.
Anche la crescita media annua assoluta viene calcolata utilizzando la formula della media aritmetica
Deviazione standard: concetto e tipologie. Classificazione e caratteristiche della categoria "Deviazione quadratica media" 2017, 2018.
La radice quadrata della varianza è chiamata deviazione standard dalla media, che viene calcolata come segue:
Una trasformazione algebrica elementare della formula della deviazione standard la porta alla forma seguente:
Questa formula risulta spesso più conveniente nella pratica di calcolo.
La deviazione standard, proprio come la deviazione lineare media, mostra quanto in media i valori specifici di una caratteristica si discostano dal loro valore medio. La deviazione standard è sempre maggiore della deviazione lineare media. Tra loro esiste la seguente relazione:
Conoscendo questo rapporto, puoi utilizzare gli indicatori noti per determinare l'ignoto, ad esempio, ma (IO calcolare a e viceversa. La deviazione standard misura la dimensione assoluta della variabilità di una caratteristica ed è espressa nelle stesse unità di misura dei valori della caratteristica (rubli, tonnellate, anni, ecc.). È una misura assoluta di variazione.
Per segnali alternativi, ad esempio, la presenza o l'assenza di istruzione superiore, assicurazione, le formule per la dispersione e la deviazione standard sono le seguenti:
Mostriamo il calcolo della deviazione standard secondo i dati di una serie discreta che caratterizza la distribuzione degli studenti in una delle facoltà universitarie per età (Tabella 6.2).
Tabella 6.2.

I risultati dei calcoli ausiliari sono riportati nelle colonne 2-5 della tabella. 6.2.
L'età media di uno studente, anni, è determinata dalla formula della media aritmetica ponderata (colonna 2):
![]()
Le deviazioni al quadrato dell'età individuale dello studente dalla media sono contenute nelle colonne 3-4, mentre i prodotti delle deviazioni al quadrato e le frequenze corrispondenti sono contenuti nella colonna 5.
Troviamo la varianza dell’età, degli anni, degli studenti utilizzando la formula (6.2):
![]()
Allora o = l/3,43 1,85 *oda, cioè Ciascun valore specifico dell’età di uno studente si discosta dalla media di 1,85 anni.
Il coefficiente di variazione
Nel suo valore assoluto, la deviazione standard dipende non solo dal grado di variazione della caratteristica, ma anche dai livelli assoluti delle opzioni e dalla media. Pertanto, è impossibile confrontare direttamente le deviazioni standard delle serie di variazioni con livelli medi diversi. Per poter effettuare tale confronto, è necessario trovare la quota della deviazione media (lineare o quadratica) nella media aritmetica, espressa in percentuale, cioè calcolare misure relative di variazione.
Coefficiente di variazione lineare calcolato dalla formula
Il coefficiente di variazione determinato dalla seguente formula:
Nei coefficienti di variazione viene eliminata non solo l'incomparabilità associata a diverse unità di misura della caratteristica studiata, ma anche l'incomparabilità che deriva dalle differenze nel valore delle medie aritmetiche. Inoltre, gli indicatori di variazione caratterizzano l'omogeneità della popolazione. La popolazione è considerata omogenea se il coefficiente di variazione non supera il 33%.
Secondo la tabella. 6.2 e i risultati del calcolo ottenuti sopra, determiniamo il coefficiente di variazione, %, secondo la formula (6.3):
![]()
Se il coefficiente di variazione supera il 33%, ciò indica l'eterogeneità della popolazione studiata. Il valore ottenuto nel nostro caso indica che la popolazione degli studenti per età è omogenea nella composizione. Pertanto, una funzione importante della generalizzazione degli indicatori di variazione è quella di valutare l’affidabilità delle medie. Il meno c1, a2 e V, tanto più omogeneo è l'insieme dei fenomeni risultanti e tanto più affidabile è la media risultante. Secondo la “regola dei tre sigma” considerata dalla statistica matematica, in serie distribuite normalmente o vicine ad esse, deviazioni dalla media aritmetica non superiori a ±3st si verificano in 997 casi su 1000. Quindi, conoscendo X e a, puoi avere un'idea iniziale generale della serie di variazioni. Se, ad esempio, lo stipendio medio di un dipendente di un'azienda è di 25.000 rubli e a è pari a 100 rubli, allora con una probabilità prossima alla certezza possiamo dire che i salari dei dipendenti dell'azienda oscillano all'interno dell'intervallo (25.000 ± ± 3 x 100 ) cioè da 24.700 a 25.300 rubli.
La radice quadrata media o deviazione standard è un indicatore statistico che valuta la quantità di fluttuazione di un campione numerico attorno al suo valore medio. Quasi sempre, la maggior parte dei valori è distribuita entro più o meno una deviazione standard dalla media.
Definizione
La deviazione standard è la radice quadrata della media aritmetica della somma delle deviazioni quadrate dalla media. Rigoroso e matematico, ma assolutamente incomprensibile. Questa è una descrizione verbale della formula per il calcolo della deviazione standard, ma per comprendere il significato di questo termine statistico, comprendiamo tutto in ordine.
Immagina un poligono di tiro, un bersaglio e una freccia. Il cecchino spara a un bersaglio standard, dove colpire il centro dà 10 punti, a seconda della distanza dal centro il numero di punti diminuisce, e colpire le aree estreme dà solo 1 punto. Il tiro di ogni tiratore è un valore intero casuale compreso tra 1 e 10. Un bersaglio crivellato di proiettili è un perfetto esempio della distribuzione di una variabile casuale.
Valore atteso
Il nostro tiratore alle prime armi si è esercitato a lungo nel tiro e ha notato che con una certa probabilità raggiungeva valori diversi. Diciamo che, sulla base di un gran numero di tiri, ha scoperto di colpirne 10 con una probabilità del 15%. I restanti valori hanno ricevuto le loro probabilità:
- 9 - 25 %;
- 8 - 20 %;
- 7 - 15 %;
- 6 - 15 %;
- 5 - 5 %;
- 4 - 5 %.
Adesso si prepara a fare un altro tentativo. Quale valore ha più probabilità di raggiungere? L’aspettativa matematica ci aiuterà a rispondere a questa domanda. Conoscendo tutte queste probabilità, possiamo determinare l'esito più probabile del tiro. La formula per calcolare l'aspettativa matematica è abbastanza semplice. Indichiamo il valore del tiro come C e la probabilità come p. L'aspettativa matematica sarà uguale alla somma del prodotto dei valori corrispondenti e delle loro probabilità:
Definiamo l'aspettativa per il nostro esempio:
- M = 10 × 0,15 + 9 × 0,25 + 8 × 0,2 + 7 × 0,15 + 6 × 0,15 + 5 × 0,05 + 4 × 0,05
- M = 7,75
Quindi, è molto probabile che il tiratore colpisca la zona dei 7 punti. Quest'area sarà quella colpita più pesantemente, il che è un eccellente risultato dei colpi più frequenti. Per qualsiasi variabile casuale, il valore atteso indica il valore più comune o il centro di tutti i valori.
Dispersione
La dispersione è un altro indicatore statistico che illustra la diffusione di un valore. Il nostro bersaglio è densamente crivellato di proiettili e la dispersione ci permette di esprimere numericamente questo parametro. Se l'aspettativa matematica mostra il centro dei tiri, allora la dispersione è la loro diffusione. In sostanza, per dispersione si intende l'aspettativa matematica delle deviazioni dei valori dal valore atteso, cioè il quadrato medio delle deviazioni. Ogni valore viene elevato al quadrato in modo che gli scostamenti siano solo positivi e non si annullino a vicenda nel caso di numeri identici con segno opposto.
D[X] = M − (M[X]) 2
Calcoliamo la diffusione dei colpi per il nostro caso:
- M = 10 2 × 0,15 + 9 2 × 0,25 + 8 2 × 0,2 + 7 2 × 0,15 + 6 2 × 0,15 + 5 2 × 0,05 + 4 2 × 0,05
- M = 62,85
- D[X] = M − (M[X]) 2 = 62,85 − (7,75) 2 = 2,78
Quindi la nostra deviazione è 2,78. Ciò significa che dall'area del bersaglio con un valore di 7,75 i fori dei proiettili sono distanziati di 2,78 punti. Tuttavia, nella sua forma pura, il valore della varianza non viene utilizzato: il risultato è il quadrato del valore, nel nostro esempio è un punto quadrato, ma in altri casi potrebbe essere chilogrammi quadrati o dollari quadrati. La dispersione come valore quadrato non è informativa, quindi rappresenta un indicatore intermedio per determinare la deviazione standard: l'eroe del nostro articolo.
Deviazione standard
Per convertire la varianza in punti, chilogrammi o dollari significativi, utilizziamo la deviazione standard, che è la radice quadrata della varianza. Calcoliamolo per il nostro esempio:
S = quadrato(D) = quadrato(2,78) = 1,667
Abbiamo ricevuto i punti e ora possiamo usarli per connetterci con l'aspettativa matematica. Il risultato più probabile del tiro in questo caso sarebbe espresso come 7,75 più o meno 1,667. Questo basta per rispondere, ma possiamo anche dire che è quasi certo che il tiratore colpirà la zona del bersaglio tra le 6.08 e le 9.41.
La deviazione standard o sigma è un indicatore informativo che illustra la diffusione di un valore rispetto al suo centro. Maggiore è il sigma, maggiore è la diffusione mostrata dal campione. Questo è un coefficiente ben studiato e l'interessante regola dei tre sigma è nota per la distribuzione normale. È stato stabilito che il 99,7% dei valori di una quantità distribuita normalmente si trova nell'ordine di più o meno tre sigma dalla media aritmetica.
Diamo un'occhiata a un esempio
Volatilità delle coppie di valute
È noto che i metodi della statistica matematica sono ampiamente utilizzati nel mercato dei cambi. Molti terminali di trading dispongono di strumenti integrati per calcolare la volatilità di un asset, che dimostra una misura della volatilità del prezzo di una coppia di valute. Naturalmente, i mercati finanziari hanno le proprie specifiche per il calcolo della volatilità, come i prezzi di apertura e chiusura delle borse, ma ad esempio possiamo calcolare il sigma per le ultime sette candele giornaliere e stimare approssimativamente la volatilità settimanale.
La coppia di valute sterlina/yen è giustamente considerata l’asset più volatile nel mercato Forex. Supponiamo che teoricamente durante la settimana il prezzo di chiusura della Borsa di Tokyo assuma i seguenti valori:
145, 147, 146, 150, 152, 149, 148.
Inseriamo questi dati nella calcolatrice e calcoliamo il sigma pari a 2,23. Ciò significa che in media lo yen giapponese è cambiato di 2,23 yen ogni giorno. Se tutto fosse così meraviglioso, i trader guadagnerebbero milioni da tali movimenti.
Conclusione
La deviazione standard viene utilizzata nell'analisi statistica di campioni numerici. Questo è un coefficiente utile per valutare la diffusione dei dati, poiché due insiemi con apparentemente lo stesso valore medio possono essere completamente diversi nella diffusione dei valori. Utilizza il nostro calcolatore per trovare piccoli sigma campione.
- In contatto con 0
- Google+ 0
- OK 0
- Facebook 0