Il corso introduce gli studenti ai principali compiti e metodi della statistica applicata.
Obiettivi del corso- collegare teoria e pratica, insegnare agli studenti a "vedere" problemi statistici in varie aree tematiche e applicare correttamente i metodi della statistica applicata, mostrare le possibilità e i limiti dei metodi statistici utilizzando esempi pratici. Il corso è più metodologico che matematico e non contiene dimostrazioni di teoremi.
Ciascun metodo è descritto secondo un unico schema:
- formulazione del problema;
- esempi di problemi applicati nel campo della biologia, economia, sociologia, produzione, medicina;
- presupposti di base e limiti di applicabilità;
- descrizione del metodo (per i metodi di verifica delle ipotesi statistiche: ipotesi nulla e alternative, statistica, sua distribuzione zero);
- vantaggi, svantaggi, limitazioni, “insidie”;
- confronto con altri metodi.
Il corso viene insegnato dal 2007 agli studenti del 4° anno del Dipartimento di Metodi Matematici di Previsione dell'Università Panrussa di Matematica e Conservatorio dell'Università Statale di Mosca e agli studenti del 4° anno della Facoltà di Management e Matematica Applicata dell'Istituto di Mosca di Fisica e Tecnologia dal 2011. Si presuppone che gli studenti abbiano già seguito corsi di teoria della probabilità e statistica matematica.
Programma del corso
introduzione
Panoramica delle informazioni necessarie dalla teoria della probabilità e dalla statistica matematica.
- I concetti di campionamento semplice e statistica. Esempi di statistica: momenti, asimmetria e curtosi, serie di variazioni e statistica ordinale, distribuzione empirica.
- Stime statistiche puntuali e loro proprietà: imparzialità, coerenza, ottimalità, robustezza.
- Stime intervallari, concetti di intervallo di confidenza e livello di confidenza. Intervalli di confidenza per media e mediana.
- Distribuzioni comunemente usate: normale, chi-quadrato, Fisher, Student, Bernoulli, binomiale, Poisson.
- Verifica di ipotesi statistiche, concetti base: livello di significatività, livello di significatività raggiunto (p-value), errori di tipo I e II. Alternative unilaterali e bilaterali.
- Proprietà dei livelli di significatività raggiunti. Significato statistico e pratico.
- Proprietà dei criteri: imparzialità, coerenza, potenza.
Verifica di ipotesi parametriche
- Test di normalità: test del chi quadrato (Pearson), test di Shapiro-Wilk, test basati sulle differenze tra funzioni di distribuzione empiriche e teoriche, test di Kolmogorov-Smirnov (Lilliefors). Test semplificato di normalità mediante asimmetria e curtosi: il test di Harke-Beer.
- Criteri parametrici normali per la verifica delle ipotesi: ipotesi di posizione, ipotesi di scattering.
- Ipotesi sulle medie: test t e z di Student per uno e due campioni, campioni correlati
- Ipotesi di dispersione: test del chi quadrato e di Fisher.
- Ipotesi sui valori del parametro della distribuzione di Bernoulli: confronto del valore del parametro con quello dato, confronto dei parametri delle distribuzioni di due campioni (casi di campioni correlati e indipendenti).
- Intervallo di confidenza per il parametro della distribuzione di Bernoulli: Wald, Wilson. Intervalli di confidenza di Wilson per la differenza tra i parametri di due campioni.
Test di ipotesi non parametrici
Test di ipotesi multiple
Analisi della varianza (ANOVA)
- Modello a un fattore. Campioni indipendenti: test di Fisher, Kruskal-Wallis, Jonkheer. Esempi collegati: i test di Fisher, Friedman e Page. Assunzione di sfericità.
- Modello ad effetti casuali, separazione della varianza.
- Modello a effetti fissi, perfezionamento delle differenze: metodi LSD e HSD, test di Nemenyi e Dunnett.
- Verifica dell'ipotesi dell'uguaglianza delle varianze: i test di Bartlett e Flyner-Killian.
- modello a due fattori. Interazione di fattori, sua interpretazione. Analisi normale bidirezionale. Progettazione gerarchica.
Analisi delle dipendenze
Analisi di regressione lineare
Generalizzazioni della regressione lineare
- Modelli lineari generalizzati. funzione di collegamento. Stima dei parametri con il metodo della massima verosimiglianza.
- Intervalli di confidenza e stima della significatività dei coefficienti, test di Wald e rapporti di verosimiglianza.
- Misure di qualità dei modelli lineari generalizzati: anomalia, criteri informativi.
- Enunciazione del problema della regressione logistica. Logit, interpretazione dei coefficienti di regressione logistica.
- Test di linearità logit: grafici a dispersione smussati, polinomi frazionari.
- Classificazione basata sulla regressione logistica: sensibilità, specificità, scelta della soglia.
- Regressione del segno di conteggio. Modello di Poisson.
- L'ipotesi sull'uguaglianza dell'aspettativa e della varianza e la sua verifica. Modello binomiale negativo. Stima stabile della varianza dei coefficienti.
Analisi delle serie temporali
Analisi sequenziale
[Wald, Mukhopadhyay]
- Applicazione in problemi di verifica di ipotesi sui valori del parametro della distribuzione binomiale: confronto di un valore con uno dato, confronto di due valori.
- Applicazione nei compiti di verifica di ipotesi sui valori dei parametri della distribuzione normale: confronto del valore medio con quelli dati (opzioni simmetriche e asimmetriche), confronto del valore della varianza con quello dato.
- Intervalli di confidenza consecutivi per la media della popolazione normale con varianza sconosciuta (procedura sequenziale a due fasi). Procedure per la differenza delle medie di due popolazioni normali, casi di varianze uguali e disuguali.
- Intervalli di confidenza sequenziali non parametrici per la media e la mediana.
Analisi causa-effetto
- Indecidibilità del paradosso di Simpson nel quadro della statistica classica.
- Grafi causali, catene, forcelle, collisori. D-separabilità.
- interventi. Valutazione dell'effetto sulla base di dati osservativi. Chirurgia del grafico e formula di aggiustamento.
- Regola dell'effetto causale. Opzioni per l'assenza dei genitori: regola della porta sul retro, regola della porta d'ingresso.
- Punteggio di propensione, ponderazione probabilistica inversa.
- Grafici nei modelli lineari. Collegamento con le equazioni strutturali.
Letteratura
- Wald, A. Analisi sequenziale. - M.: Fizmatlit, 1960.
- Lagutin, M.B. Statistica matematica visiva. In due volumi. - M.: P-centro, 2003.
- Kobzar, A.I. Statistica matematica applicata. - M.: Fizmatlit, 2006.
- Agresti A. analisi categorica dei dati. -Hoboken: John Wiley & Figli, 2013.
- Bonnini, S., Corain, L., Marozzi, M., Salmaso S. Test di ipotesi non parametrici: metodi di rango e permutazione con applicazioni in R. - Hoboken: John Wiley & Sons, 2014.
- Bretz, F., Hothorn, T., Westfall, P. Confronti multipli utilizzando R. - Boca Raton: Chapman e Hall/CRC, 2010.
- Cameron, A.A., Trivedi, P.K. Analisi di regressione dei dati di conteggio. - Cambridge: Cambridge University Press, 2013.
- Dickhaus, T. Inferenza statistica simultanea con applicazioni nelle scienze della vita. -Heidelberg: Springer, 2014.
- Buono, p. Test di permutazione, parametrici e bootstrap delle ipotesi: una guida pratica ai metodi di ricampionamento per testare le ipotesi. -New York: Springer, 2005.
- Hastie, T., Tibshirani, R., Friedman, J. Gli elementi dell'apprendimento statistico, 2a edizione. - Springer, 2009. - 533 pag. ()
- Hosmer, D.W., Lemeshow S., Sturdivant, R.X. Regressione logistica applicata. -Hoboken: John Wiley & Figli, 2013.
- Hyndman, RJ, Athanasopoulos G. Previsione: principi e pratica. - OTexts, 2015. https://www.otexts.org/book/fpp
- Kanji, G.K. 100 test statistici. - Londra: pubblicazioni SAGE, 2006.
- Mukhopadhyay, N., de Silva, B. M. Metodi sequenziali e loro applicazioni. - Boca Raton: Chapman e Hall/CRC, 2009.
- Olson, U. Modelli lineari generalizzati: un approccio applicato. - Lund: Letteratura studentesca, 2004.
- Pearl J., Glymour M., Jewell N.P. Inferenza causale in statistica: un primer. - Chichester: John Wiley & Figli, 2016.
- Tabachnick, BG, Fidell, L.S. Utilizzo della statistica multivariata. - Boston: Pearson Education, 2012.
- Wooldridge, J. Econometria introduttiva: un approccio moderno. - Mason: Apprendimento Cengage sud-occidentale, 2013.
Clienti, consumatori: questa non è solo una raccolta di informazioni, ma uno studio a tutti gli effetti. E lo scopo di ogni ricerca è un'interpretazione scientificamente fondata dei fatti studiati. Il materiale primario deve essere elaborato, cioè ordinato e analizzato.Dopo il sondaggio degli intervistati avviene l'analisi dei dati della ricerca. Questo è un passo fondamentale. Si tratta di un insieme di tecniche e metodi volti a verificare quanto fossero vere le ipotesi e le ipotesi, nonché a rispondere alle domande poste. Questa fase è forse la più difficile in termini di sforzi intellettuali e qualifiche professionali, ma consente di ottenere le informazioni più utili dai dati raccolti. I metodi di analisi dei dati sono diversi. La scelta di un metodo specifico dipende, prima di tutto, dalle domande a cui vogliamo ottenere una risposta. Si possono distinguere due classi di procedure di analisi:
- unidimensionale (descrittivo) e
- multidimensionale.
Lo scopo dell'analisi univariata è descrivere una caratteristica del campione in un particolare momento. Consideriamo più in dettaglio.
Tipi di analisi dei dati unidimensionali
Ricerca quantitativa
Analisi descrittiva
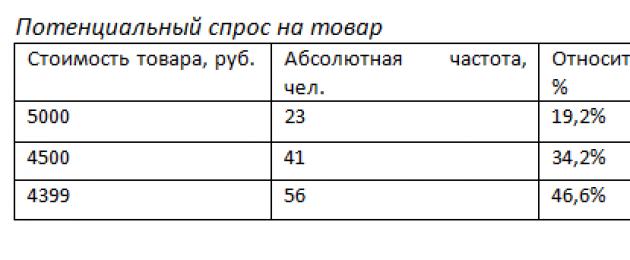
La statistica descrittiva (o descrittiva) è il metodo base e più comune di analisi dei dati. Immagina di condurre un sondaggio con l'obiettivo di compilare un ritratto del consumatore del prodotto. Gli intervistati indicano il loro sesso, età, stato civile e professionale, preferenze di consumo, ecc., e le statistiche descrittive forniscono informazioni sulla base delle quali verrà costruito l'intero ritratto. Oltre alle caratteristiche numeriche, vengono creati una varietà di grafici per aiutare a visualizzare i risultati dell'indagine. Tutta questa varietà di dati secondari è accomunata dal concetto di “analisi descrittiva”. I dati numerici ottenuti durante lo studio sono spesso presentati nelle relazioni finali sotto forma di tabelle di frequenza. Le tabelle possono rappresentare diversi tipi di frequenze. Diamo un'occhiata ad un esempio: Domanda potenziale del prodotto 
- La frequenza assoluta mostra quante volte una particolare risposta viene ripetuta nel campione. Ad esempio, 23 persone comprerebbero il prodotto proposto del valore di 5.000 rubli, 41 persone del valore di 4.500 rubli. e 56 persone - 4399 rubli.
- La frequenza relativa mostra la proporzione di questo valore rispetto alla dimensione totale del campione (23 persone - 19,2%, 41 - 34,2%, 56 - 46,6%).
- La frequenza cumulativa o cumulativa indica la proporzione di elementi del campione che non supera un determinato valore. Ad esempio, un cambiamento nella percentuale di intervistati pronti ad acquistare un particolare prodotto con una diminuzione del prezzo (il 19,2% degli intervistati è pronto ad acquistare beni per 5.000 rubli, il 53,4% - da 4.500 a 5.000 rubli) e 100% - da 4399 a 5000 rub.).
Insieme alle frequenze, l'analisi descrittiva prevede il calcolo di varie statistiche descrittive. Fedeli al loro nome, forniscono informazioni di base sui dati ricevuti. Per chiarire, l'uso di statistiche specifiche dipende dalle scale in cui sono presentate le informazioni sulla fonte. Scala nominale
utilizzato per fissare oggetti che non hanno un ordine classificato (sesso, luogo di residenza, marca preferita, ecc.). Per questo tipo di array di dati è impossibile calcolare indicatori statistici significativi, ad eccezione di moda— il valore più frequente della variabile. La situazione è un po’ migliore in termini di analisi scala ordinale
. Qui diventa possibile, insieme alla moda, calcolare mediane– valore che divide il campione in due parti uguali. Ad esempio, se ci sono diversi intervalli di prezzo per un prodotto (500-700 rubli, 700-900, 900-1100 rubli), la mediana consente di impostare il costo esatto, più o meno di quello che i consumatori sono disposti ad acquistare o, al contrario, rifiutarsi di acquistare. Le più ricche di tutte le statistiche possibili sono scale quantitative
, che sono serie di valori numerici che hanno intervalli uguali tra loro e sono misurabili. Esempi di tali scale sono il livello di reddito, l’età, il tempo dedicato agli acquisti, ecc. In questo caso diventano disponibili le seguenti informazioni le misure: media, intervallo, deviazione standard, errore standard della media. Naturalmente il linguaggio dei numeri è piuttosto “secco” e per molti molto incomprensibile. Per questo motivo, l'analisi descrittiva è integrata dalla visualizzazione dei dati costruendo vari diagrammi e grafici, come istogrammi, grafici a linee, a torta o a dispersione. 
Tabelle di contingenza e di correlazione
Tabelle di contingenzaè un mezzo per rappresentare la distribuzione di due variabili, progettato per esplorare la relazione tra loro. Le tabelle incrociate possono essere considerate come un particolare tipo di analisi descrittiva. È anche possibile presentare informazioni sotto forma di frequenze assolute e relative, visualizzazione grafica sotto forma di istogrammi o grafici a dispersione. Le tabelle di contingenza sono più efficaci nel determinare la relazione tra variabili nominali (ad esempio, tra il genere e il fatto del consumo di un prodotto). In generale, la tabella di contingenza si presenta così. Rapporto tra genere e fruizione dei servizi assicurativi

Inviare il tuo buon lavoro nella knowledge base è semplice. Utilizza il modulo sottostante
Studenti, dottorandi, giovani scienziati che utilizzano la base di conoscenze nei loro studi e nel loro lavoro ti saranno molto grati.
Ospitato su http://www.allbest.ru/
- 3. Serie di dinamiche
- Letteratura
1. Valori assoluti e relativi
Come risultato della sintesi e del raggruppamento del materiale statistico, le informazioni più diverse sui fenomeni e sui processi studiati sono nelle mani del ricercatore. Tuttavia, soffermarsi sui risultati ottenuti sarebbe un grosso errore, perché, anche raggruppati secondo determinati criteri e rappresentati in forma tabellare o grafica, questi dati sono pur sempre solo una sorta di illustrazione, un risultato intermedio che deve essere analizzato - in questo caso , statistico. Statisticoanalisi - Questo prestazione studiato oggetto V qualità smembrato sistemi, quelli. complesso elementi E connessioni, generando V il suo interazione biologico Totale.
Come risultato di tale analisi, dovrebbe essere costruito un modello dell'oggetto in esame e, poiché stiamo parlando di statistica, durante la costruzione del modello dovrebbero essere utilizzati elementi e relazioni statisticamente significativi.
L'analisi statistica, infatti, è finalizzata all'individuazione di tali elementi e relazioni significative.
Assolutoindicatori(valori) - valori totali calcolati o presi da rapporti statistici riepilogativi senza alcuna trasformazione. Gli indicatori assoluti sono sempre nominali e si riflettono nelle unità di misura fissate durante la compilazione del programma di osservazione statistica (il numero di procedimenti penali avviati, il numero di reati commessi, il numero di divorzi, ecc.).
Gli indicatori assoluti sono fondamentali per qualsiasi ulteriore operazione statistica, ma essi stessi sono di scarsa utilità per l'analisi. Utilizzando indicatori assoluti, ad esempio, è difficile giudicare il livello di criminalità in diverse città o regioni ed è praticamente impossibile rispondere alla domanda su dove la criminalità è più alta e dove è più bassa, poiché le città o le regioni possono differire significativamente in termini di popolazione , territorio e altri parametri importanti.
parentele quantità in statistica sono indicatori generalizzati che rivelano la forma numerica del rapporto tra due valori statistici confrontati. Quando si calcolano i valori relativi, vengono spesso confrontati due valori assoluti, ma è possibile confrontare sia i valori medi che quelli relativi, ottenendo nuovi indicatori relativi. L'esempio più semplice per calcolare un valore relativo è la risposta alla domanda: quante volte un numero è maggiore di un altro?
Iniziando a considerare i valori relativi, è necessario tenere conto di quanto segue. In linea di principio, tutto può essere paragonato, anche le dimensioni lineari di un foglio di carta A4 con il numero di prodotti fabbricati dalla fabbrica di porcellana Lomonosov. Tuttavia, un simile confronto non ci darà nulla. La condizione più importante per un calcolo fruttuoso delle quantità relative può essere formulata come segue:
1. Le unità di misura delle grandezze confrontate devono essere uguali o abbastanza comparabili. Il numero dei crimini, dei casi penali e dei condannati sono indicatori correlati, vale a dire correlati, ma non comparabili in termini di unità di misura. In un procedimento penale possono essere presi in considerazione più reati e condannato un gruppo di persone; Diversi detenuti possono commettere un reato e, viceversa, un detenuto può commettere molte azioni. Il numero di crimini, casi e condanne è paragonabile alla popolazione, al numero del personale del sistema di giustizia penale, al tenore di vita delle persone e ad altri dati dello stesso anno. Inoltre, entro un anno gli indicatori considerati sono abbastanza comparabili tra loro.
2. I dati comparabili devono necessariamente corrispondere tra loro in termini di tempo o di territorio in cui vengono ricevuti, o di entrambi.
Assoluto valore, Con Quale rispetto altro Vemaschere, chiamato base O base confronti, UN confrontareEscolpito indice - grandezza confronti. Ad esempio, quando si calcola il rapporto tra le dinamiche della criminalità in Russia nel periodo 2000-2010. I dati del 2000 costituiranno il riferimento. Possono essere presi come unità (quindi il valore relativo sarà espresso sotto forma di coefficiente), come 100 (in percentuale). A seconda della dimensione dei valori confrontati viene scelta la forma più conveniente, indicativa e visiva di espressione del relativo valore.
Se il valore da confrontare è molto più grande della base, il rapporto risultante è meglio espresso in termini di coefficienti. Ad esempio, la criminalità in un certo periodo (in anni) è aumentata di 2,6 volte. L'espressione in tempi in questo caso sarà più indicativa che in percentuale. In percentuale, i valori relativi sono espressi quando il valore di confronto non differisce molto dalla base.
I valori relativi utilizzati nelle statistiche, comprese le statistiche legali, sono di diversi tipi. I seguenti tipi di valori relativi vengono utilizzati nelle statistiche legali:
1. relazioni che caratterizzano la struttura della popolazione, o relazioni distributive;
2. il rapporto della parte con il tutto, o il rapporto di intensità;
3. relazioni che caratterizzano la dinamica;
4. Relazioni di grado e comparazione.
Parentegrandezzadistribuzione - Questo parente valore, espresso V per cento individuale parti aggregati studiato fenomeni(reati, penali, cause civili, cause legali, cause, misure di prevenzione, ecc.) A loro generale totale, accettato dietro 100% . Questo è il tipo più comune (e più semplice) di dati relativi utilizzati nelle statistiche. Si tratta, ad esempio, della struttura della criminalità (per tipologia di reato), della struttura delle condanne (per tipologia di reato, per età dei condannati), ecc.
valore assoluto dell'analisi statistica
Atteggiamentointensità(rapporto parte-intero) - un valore relativo generalizzante che riflette la prevalenza di una particolare caratteristica nell'osservato aggregati.
L’indicatore di intensità più comune utilizzato nelle statistiche giuridiche è l’intensità della criminalità. . L’intensità della criminalità si riflette solitamente nel tasso di criminalità , quelli. il numero di reati ogni 100 o 10mila abitanti.
KP \u003d (P * 100000) / N
dove P è il numero assoluto di crimini registrati, N è la popolazione assoluta.
Un prerequisito che determina la possibilità stessa di calcolare tali indicatori, come menzionato sopra, è che tutti gli indicatori assoluti utilizzati siano presi in un territorio e per un periodo di tempo.
Relazione,caratterizzantedinamica, rappresentare generalizzando parente le quantità, mostrando modifica In tempo quelli O altro indicatori legale statistiche. L'intervallo di tempo viene solitamente considerato un anno.
Per la base (base) pari a 1, o 100%, vengono prese le informazioni sulla caratteristica studiata di un determinato anno, che era qualcosa di caratteristico del fenomeno in studio. I dati dell'anno base fungono da base fissa, alla quale vengono percentualizzati gli indicatori degli anni successivi.
Le attività di analisi statistica spesso richiedono confronti annuali (o altri periodi) quando base accettato dati tutti precedente dell'anno(mese o altro periodo). Tale base si chiama mobile. Questo viene solitamente utilizzato nell'analisi delle serie temporali (serie di dinamiche).
RelazionegradiEconfronti consentono di confrontare diversi indicatori al fine di identificare quale valore è molto maggiore dell'altro, in che misura un fenomeno differisce da un altro o è simile ad esso, cosa è comune e cosa diverso nei processi statistici osservati, ecc.
Un indice è un indicatore relativo di confronto appositamente creato (nel tempo, nello spazio, rispetto a una previsione, ecc.), che mostra quante volte il livello del fenomeno in studio differisce dal livello dello stesso fenomeno in altre condizioni. Gli indici più comuni si trovano nelle statistiche economiche, sebbene svolgano un certo ruolo anche nell'analisi dei fenomeni giuridici.
Gli indici sono indispensabili nei casi in cui è necessario confrontare indicatori disparati, la cui semplice somma è impossibile. Pertanto, gli indici sono generalmente definiti come numeri-indicatoriPermisurazionimezzoAltoparlantiaggregatieterogeneoelementi.
Nelle statistiche, gli indici sono solitamente indicati con la lettera I (i). Lettera maiuscola o lettera maiuscola: dipende se si tratta di un indice individuale (privato) o generale.
Individualeindici(i) riflettere il rapporto tra l'indicatore del periodo corrente e il corrispondente indicatore del periodo a confronto.
Consolidatoindici vengono utilizzati nell'analisi della correlazione di fenomeni socioeconomici complessi e sono costituiti da due parti: il valore effettivamente indicizzato e la commisurazione ("peso").
2. Medie e loro applicazione nella statistica giuridica
Il risultato dell'elaborazione degli indicatori assoluti e relativi è la costruzione delle serie distributive. Riga distribuzione - QuestoordinatoDiqualitàOquantitativoin primo pianodistribuzioneunitàaggregati. L'analisi di queste serie è la base di qualsiasi analisi statistica, non importa quanto complessa risulti essere in futuro.
Una serie di distribuzione può essere costruita sulla base di caratteristiche qualitative o quantitative. Nel primo caso si chiama attributivo, nel secondo - variazionale. In questo caso, viene chiamata la differenza in un tratto quantitativo variazione, e questo segno stesso - opzione. È con le serie variazionali che la statistica giuridica ha più spesso a che fare.
Una serie variazionale è sempre composta da due colonne (grafico). Si indica il valore di un attributo quantitativo in ordine crescente, che, appunto, si chiamano opzioni, che vengono indicate X. L'altra colonna (colonna) indica il numero di unità caratteristiche dell'una o dell'altra variante. Si chiamano frequenze e sono indicate con la lettera latina F.
Tabella 2.1
|
Opzione X |
|||||
|
Frequenza F |
La frequenza di manifestazione dell'uno o dell'altro tratto è molto importante quando si calcolano altri indicatori statistici significativi, vale a dire le medie e gli indicatori di variazione.
Le serie di variazioni, a loro volta, possono esserlo discreto O intervallo. Le serie discrete, come suggerisce il nome, sono costruite sulla base di caratteristiche che variano in modo discreto, mentre le serie di intervalli sono costruite sulla base di variazioni continue. Quindi, ad esempio, la distribuzione dei delinquenti per età può essere discreta (18, 19,20 anni, ecc.) o continua (fino a 18 anni, 18-25 anni, 25-30 anni, ecc.). Inoltre, le serie di intervalli stesse possono essere costruite sia su base discreta che continua. Nel primo caso i confini degli intervalli adiacenti non si ripetono; nel nostro esempio, gli intervalli saranno così: fino a 18 anni, 18-25, 26-30, 31-35, ecc. Tale serie si chiama continuodiscretoriga. intervallorigaConcontinuovariazione implica la coincidenza del limite superiore dell'intervallo precedente con il limite inferiore di quello successivo.
Il primo indicatore che descrive la serie variazionale è medio le quantità. Svolgono un ruolo importante nella statistica giuridica, poiché solo con il loro aiuto è possibile caratterizzare le popolazioni secondo una caratteristica variabile quantitativa con cui possono essere confrontate. Con l'aiuto dei valori medi è possibile confrontare i complessi dei fenomeni giuridicamente rilevanti che ci interessano secondo determinate caratteristiche quantitative e trarre da questi confronti le necessarie conclusioni.
mediole quantità riflettere maggior parte generale tendenza (regolarità), inerente all'intera massa di fenomeni studiati. Si manifesta nel tipico caratteristica quantitativa, cioè nel valore medio di tutti gli indicatori (variabili) disponibili.
La statistica ha sviluppato molti tipi di medie: aritmetica, geometrica, cubica, armonica, ecc. Tuttavia, non sono praticamente utilizzati nelle statistiche legali, quindi considereremo solo due tipi di medie: la media aritmetica e la media geometrica.
La media più comune e conosciuta è mediaaritmetica. Per calcolarlo, si calcola la somma degli indicatori e la si divide per il numero totale di indicatori. Ad esempio, una famiglia di 4 persone è composta da genitori di 38 e 40 anni e due figli di 7 e 10 anni. Sommiamo l'età: 38+40+7+10 e dividiamo la somma risultante di 95 per 4. L'età media della famiglia risultante è di 23,75 anni. Oppure calcoliamo il carico di lavoro medio mensile degli investigatori se un dipartimento di 8 persone risolve 25 casi al mese. Dividi 25 per 8 e ottieni 3.125 casi al mese per investigatore.
Nelle statistiche giuridiche, la media aritmetica viene utilizzata per calcolare il carico di lavoro dei dipendenti (investigatori, pubblici ministeri, giudici, ecc.), per calcolare l'aumento assoluto della criminalità, per calcolare il campione, ecc.
Tuttavia, nell'esempio precedente, il carico di lavoro mensile medio per investigatore è stato calcolato in modo errato. Il fatto è che la semplice media aritmetica non tiene conto frequenza tratto studiato. Nel nostro esempio, il carico di lavoro mensile medio di un investigatore è corretto e informativo quanto la "temperatura media in ospedale" di un noto aneddoto, che, come sapete, è la temperatura ambiente. Per tenere conto della frequenza delle manifestazioni del tratto studiato nel calcolo della media aritmetica, viene utilizzata come segue mediaaritmeticaponderato o media per serie variazionali discrete. (Serie variazionali discrete - la sequenza di cambiamento di un segno secondo indicatori discreti (discontinui)).
Media ponderata aritmetica ( media ponderata) non presenta differenze fondamentali rispetto alla media aritmetica semplice. In esso, la somma dello stesso valore viene sostituita moltiplicando questo valore per la sua frequenza, ad es. in questo caso ogni valore (variante) viene ponderato in base alla frequenza di occorrenza.
Quindi, calcolando il carico di lavoro medio degli investigatori, dobbiamo moltiplicare il numero di casi per il numero di investigatori che hanno indagato esattamente su questo numero di casi. Di solito è conveniente presentare tali calcoli sotto forma di tabelle:
Tabella 2.2
|
Numero di casi (opzione X) |
Numero di investigatori (frequenza F) |
Opzione opera d'arte alle frequenze ( XF) |
|
2. Calcola la media ponderata effettiva con la formula:
Dove X- il numero di procedimenti penali, e F- numero di investigatori.
Pertanto, la media ponderata non è 3.125, ma 4.375. Se ci pensi, dovrebbe essere così: il carico su ogni singolo investigatore aumenta a causa del fatto che un investigatore nel nostro ipotetico dipartimento si è rivelato un fannullone o, al contrario, ha indagato su un caso particolarmente importante e complesso. Ma la questione dell'interpretazione dei risultati di uno studio statistico verrà considerata nel prossimo argomento. In alcuni casi, cioè nel caso di frequenze raggruppate con distribuzione discreta, il calcolo della media, a prima vista, non è ovvio. Supponiamo di dover calcolare la media aritmetica della distribuzione delle persone condannate per teppismo per età. La distribuzione è simile a questa:
Tabella 2.3
|
(opzione X) |
Numero di condannati (frequenza F) |
Punto medio dell'intervallo |
Opzione opera d'arte alle frequenze ( XF) |
|
|
(21-18) /2+18=19,5 |
||||
Inoltre, la media è calcolata secondo la regola generale ed è di 23,6 anni per questa serie discreta. Nel caso del cosiddetto. righe aperte, ovvero in situazioni in cui gli intervalli estremi sono determinati da "minore di X" o più X", il valore degli intervalli estremi viene impostato in modo simile agli altri intervalli.
3. Serie di dinamiche
I fenomeni sociali studiati dalle statistiche sono in costante sviluppo e cambiamento. Gli indicatori socio-giuridici possono essere presentati non solo in forma statica, riflettendo un determinato fenomeno, ma anche come un processo che si svolge nel tempo e nello spazio, nonché sotto forma di interazione delle caratteristiche studiate. In altre parole, le serie temporali mostrano lo sviluppo di un tratto, ad es. il suo cambiamento nel tempo, nello spazio o in base alle condizioni ambientali.
Questa serie è una sequenza di valori medi nei periodi di tempo specificati (per ciascun anno solare).
Per uno studio più approfondito dei fenomeni sociali e della loro analisi non è sufficiente un semplice confronto tra i livelli di una serie di dinamiche; è necessario calcolare gli indicatori derivati di una serie di dinamiche: crescita assoluta, tasso di crescita, tasso di crescita, tasso medio crescita e tassi di crescita, contenuto assoluto di aumento dell'1%.
Il calcolo degli indicatori della serie dinamica viene effettuato sulla base del confronto dei loro livelli. In questo caso, ci sono due modi per confrontare i livelli della serie dinamica:
indicatori di base, quando tutti i livelli successivi vengono confrontati con alcuni iniziali, presi come base;
indicatori a catena, quando ogni livello successivo di una serie di dinamiche viene confrontato con quello precedente.
La crescita assoluta mostra di quante unità il livello del periodo corrente è maggiore o minore rispetto al livello del periodo base o precedente per un periodo di tempo specifico.
La crescita assoluta (P) è calcolata come la differenza tra i livelli confrontati.
Crescita assoluta di base:
P b = sì io - sì basi . (f.1).
Crescita assoluta della catena:
P C = sì io - sì io -1 (f.2).
Il tasso di crescita (Tr) mostra quante volte (in quale percentuale) il livello del periodo corrente è maggiore o minore del livello del periodo base o precedente:
Tasso di crescita di base:
(f.3)
Tasso di crescita della catena:
(f.4)
Il tasso di crescita (Tpr) mostra di quanta percentuale il livello del periodo corrente è in più o in meno rispetto al livello del periodo base o precedente, preso come base di confronto, ed è calcolato come il rapporto tra la crescita assoluta e il livello assoluto , preso come base.
Il tasso di crescita può anche essere calcolato sottraendo il 100% dal tasso di crescita.
Tasso di crescita di base:
o (f.5)
Tasso di crescita della catena:
o (f.6)
Il tasso di crescita medio è calcolato dalla formula della media geometrica dei tassi di crescita di una serie di dinamiche:
(modulo 7)
dov'è il tasso di crescita medio;
- tassi di crescita per determinati periodi;
N- il numero dei tassi di crescita.
Problemi simili con esponente radice maggiore di tre, di regola, vengono risolti usando il logaritmo. Dall'algebra è noto che il logaritmo di una radice è uguale al logaritmo del valore della radice diviso per l'esponente della radice e che il logaritmo del prodotto di più fattori è uguale alla somma dei logaritmi di questi fattori.
Pertanto, il tasso di crescita medio viene calcolato prendendo la radice N laurea dalle opere dei singoli N- tassi di crescita della catena. Il tasso di crescita medio è la differenza tra il tasso di crescita medio e uno (), o il 100% quando il tasso di crescita è espresso in percentuale:
O
Se non sono presenti livelli intermedi nella serie dinamica, la crescita media e i tassi di crescita sono determinati dalla seguente formula:
(f.8)
dov'è il livello finale della serie dinamica;
- il livello iniziale della serie dinamica;
N - numero di livelli (date).
È ovvio che gli indicatori dei tassi di crescita medi e della crescita, calcolati con le formule (f.7 e f.8), hanno gli stessi valori numerici.
Il contenuto assoluto della crescita dell'1% mostra quale valore assoluto contiene la crescita dell'1% ed è calcolato come il rapporto tra la crescita assoluta e il tasso di crescita.
Contenuto assoluto dell'1% in più:
base: (f.9)
catena: (f.10)
Il calcolo e l'analisi del valore assoluto di ciascuna percentuale di crescita contribuiscono a comprendere più a fondo la natura dell'evoluzione del fenomeno oggetto di studio. I dati del nostro esempio mostrano che, nonostante le fluttuazioni nella crescita e nei tassi di crescita per i singoli anni, gli indicatori di base del contenuto assoluto della crescita dell’1% rimangono invariati, mentre gli indicatori a catena che caratterizzano le variazioni del valore assoluto della crescita dell’1% in ogni successivo anno rispetto al precedente, aumentano continuamente.
Quando si costruiscono, elaborano e analizzano serie temporali, spesso è necessario determinare i livelli medi dei fenomeni studiati per determinati periodi di tempo. La serie di intervalli cronologici medi viene calcolata a intervalli uguali dalla formula della media aritmetica semplice, con intervalli disuguali - dalla media aritmetica ponderata:
dove è il livello medio della serie di intervalli;
- livelli iniziali della serie;
N- numero di livelli.
Per la serie temporale della dinamica, a condizione che gli intervalli temporali tra le date siano uguali, il livello medio viene calcolato utilizzando la formula della media cronologica:
(f.11)
dov'è il valore cronologico medio;
sì 1 ,., sì N- il livello assoluto della serie;
N - il numero di livelli assoluti della serie dinamica.
La media cronologica dei livelli della serie momento della dinamica è pari alla somma degli indicatori di tale serie, divisa per il numero degli indicatori senza uno; in questo caso, i livelli iniziale e finale dovrebbero essere presi a metà, poiché il numero di date (momenti) è solitamente uno in più rispetto al numero di periodi.
A seconda del contenuto e della forma di presentazione dei dati iniziali (intervallo o serie temporale di dinamiche, intervalli di tempo uguali o meno) per calcolare vari indicatori sociali, ad esempio, il numero medio annuo di crimini e delitti (per tipologia), il numero medio dimensione dei saldi del capitale circolante, numero medio di delinquenti, ecc., utilizzare le espressioni analitiche appropriate.
4. Metodi statistici per lo studio delle relazioni
Nelle domande precedenti abbiamo considerato, per così dire, l'analisi delle distribuzioni "unidimensionali" - serie variazionali. Questo è un tipo di analisi statistica molto importante, ma lungi dall'essere l'unico. L'analisi delle serie variazionali è la base per tipi di analisi statistica più "avanzati", principalmente per studiointerconnessioni. Come risultato di tale studio, vengono rivelate le relazioni di causa-effetto tra i fenomeni, che consentono di determinare quali segni di cambiamento influenzano le variazioni dei fenomeni e dei processi studiati. Allo stesso tempo, i segni che causano un cambiamento negli altri sono chiamati fattoriali (fattori) e i segni che cambiano sotto la loro influenza sono chiamati efficaci.
Nella scienza statistica, esistono due tipi di connessioni tra varie caratteristiche e le loro informazioni: connessione funzionale (rigidamente determinata) e statistica (stocastica).
Per funzionaleconnessioni caratteristica è la piena corrispondenza tra la variazione dell'attributo del fattore e la variazione del valore effettivo. Questa relazione è ugualmente manifesta in tutte le unità di qualsiasi popolazione. L'esempio più semplice: un aumento della temperatura si riflette nel volume di mercurio in un termometro. In questo caso, la temperatura ambiente agisce come fattore e il volume di mercurio come caratteristica efficace.
Le relazioni funzionali sono caratteristiche dei fenomeni studiati da scienze come la chimica, la fisica, la meccanica, in cui è possibile realizzare esperimenti "puri", in cui viene eliminata l'influenza di fattori estranei. Il fatto è che una connessione funzionale tra i due è possibile solo se dipende il secondo valore (l'attributo effettivo). soltanto E esclusivamente dal primo. Negli eventi pubblici, questo è estremamente raro.
I processi socio-giuridici, che sono il risultato dell'influenza simultanea di un gran numero di fattori, sono descritti mediante relazioni statistiche, cioè relazioni stocasticamente (accidentalmente) deterministico quando valori diversi di una variabile corrispondono a valori diversi di un'altra variabile.
Il caso più importante (e comune) di dipendenza stocastica è correlazionedipendenza. Con tale dipendenza, la causa determina l'effetto non in modo inequivocabile, ma solo con un certo grado di probabilità. Un tipo separato di analisi statistica è dedicato all'identificazione di tali relazioni: l'analisi di correlazione.
Principale compito analisi di correlazione - sulla base di metodi strettamente matematici per stabilire un'espressione quantitativa della relazione che esiste tra le caratteristiche studiate. Esistono diversi approcci su come viene calcolata esattamente la correlazione e, di conseguenza, diversi tipi di coefficienti di correlazione: il coefficiente di contingenza A.A. Chuprov (per misurare la relazione tra caratteristiche qualitative), il coefficiente di associazione di K. Pearson, nonché i coefficienti di correlazione di rango di Spearman e Kendall. Nel caso generale, tali coefficienti mostrano la probabilità con cui compaiono le relazioni studiate. Di conseguenza, quanto più alto è il coefficiente, tanto più pronunciata è la relazione tra le caratteristiche.
Tra i fattori studiati possono esistere sia correlazioni dirette che inverse. Drittocorrelazionedipendenza osservato nei casi in cui la variazione dei valori del fattore corrisponde alle stesse variazioni del valore dell'attributo risultante, cioè quando aumenta il valore dell'attributo fattore, aumenta anche il valore dell'attributo effettivo, e viceversa viceversa. Ad esempio, esiste una correlazione diretta tra fattori criminogeni e criminalità ( con il segno "+"). Se un aumento dei valori di un attributo provoca cambiamenti inversi nei valori di un altro, viene chiamata tale relazione inversione. Ad esempio, maggiore è il controllo sociale in una società, minore è il tasso di criminalità (collegamento con il segno "-").
Sia il diretto che il feedback possono essere diritti e curvilinei.
Rettilineo ( relazioni lineari) compaiono quando, all'aumentare dei valori dell'attributo-fattore, si verifica un aumento (diretto) o una diminuzione (inversa) del valore dell'attributo-conseguenza. Matematicamente, tale relazione è espressa dall’equazione di regressione: A = UN + BX, Dove A - segno-conseguenza; UN E B - corrispondenti coefficienti di accoppiamento; X - fattore di segno.
Curvilineo i collegamenti sono diversi. Un aumento del valore di un attributo fattore ha un effetto non uniforme sul valore dell'attributo risultante. Inizialmente, questa relazione può essere diretta e quindi inversa. Un esempio ben noto è il rapporto tra i crimini e l’età degli autori del reato. In primo luogo, l'attività criminale delle persone cresce in modo direttamente proporzionale all'aumento dell'età dei delinquenti (fino a circa 30 anni), e poi, con l'aumentare dell'età, l'attività criminale diminuisce. Inoltre, il picco della curva di distribuzione degli autori di reato per età è spostato dalla media a sinistra (verso un’età più giovane) ed è asimmetrico.
I collegamenti diretti di correlazione possono essere unoOfattoriale, quando viene studiata la relazione tra un fattore di segno e una conseguenza di segno (correlazione di coppia). Potrebbero anche esserlo multifattoriale, quando viene studiata l'influenza di molti fattori-segni interagenti sulla conseguenza dei segni (correlazione multipla).
Ma, indipendentemente da quale dei coefficienti di correlazione venga utilizzato, indipendentemente dalla correlazione studiata, è impossibile stabilire una relazione tra i segni basata solo su indicatori statistici. L’analisi iniziale degli indicatori è sempre un’analisi qualitativo, durante il quale viene studiata e compresa la natura socio-giuridica del fenomeno. In questo caso vengono utilizzati metodi e approcci scientifici caratteristici del ramo della scienza che studia questo fenomeno (sociologia, diritto, psicologia, ecc.). Quindi, l'analisi dei raggruppamenti e delle medie consente di avanzare ipotesi, costruire modelli, determinare il tipo di connessione e dipendenza. Solo dopo viene determinata la caratteristica quantitativa della dipendenza, in effetti il coefficiente di correlazione.
Letteratura
1. Avanesov G.A. Fondamenti di previsione criminologica. Esercitazione. Mosca: Scuola Superiore del Ministero degli Affari Interni dell'URSS, 1970.
2. Avrutin K.E., Gilinsky Ya.I. Analisi criminologica della criminalità nella regione: metodologia, tecnica, tecnica. L., 1991.
3. Adamov E. e altri Economia e statistica delle imprese: libro di testo / ed. SD Ilyenkova. M.: Finanza e statistica, 2008.
4. Balakina N.N. Statistiche: Proc. - metodo. complesso. Khabarovsk: IVESEP, filiale a Khabarovsk, 2008.
5. Bluvshtein Yu.D., Volkov G.I. Serie dinamiche del crimine: libro di testo. Minsk, 1984.
6. Borovikov V.P., Borovikov I.P. STATISTICA - Analisi statistica ed elaborazione dati in ambiente Windows. M.: Casa editrice e d'informazione "Filin", 1997.
7. Borodin S.V. Controllo della criminalità: un modello teorico di un programma integrato. Mosca: Nauka, 1990.
8. Questioni di statistica // Rivista mensile scientifica e informativa del Comitato statale di statistica della Federazione Russa M., 2002-2009.
9. Gusarov V.M. Statistiche: Proc. indennità per le università. M.: UNITI-DANA, 2009.
10. Dobrynina N.V., Nimenya I.N. Statistiche: Proc. - metodo. indennità. San Pietroburgo: SPbGIEU, 2009.
11. Eliseeva I.I., Yuzbashev M.M. Teoria generale della statistica: Libro di testo per le università / Ed.I. I. Eliseeva, 4a ed. M.: Finanza e statistica, 1999.
12. Eliseeva I.I., Yuzbashev M.M. Teoria generale della statistica: libro di testo. - M.: Finanza e statistica, 1995.
13. Eremina T., Matyatina V., Plushevskaya Yu. Problemi di sviluppo dei settori dell'economia russa // Questioni di economia. 2009. N. 7.
14. Efimova M.R., Ganchenko O.I., Petrova E.V. Workshop sulla teoria generale della statistica: Proc. indennità 2a ed., rivista. e aggiuntivi M.: Finanza e statistica, 2009.
15. Efimova M.R., Petrova E.V., Rumyantsev V.N. Teoria generale della statistica: libro di testo. - M.: INFRA-M, 1998.
16. Kirillov L.A. Studio criminologico e prevenzione della criminalità da parte degli organi degli affari interni M., 1992.
17. Kosoplechev N.P., Metodi di ricerca criminologica. M., 1984.
18. Lee D.A. Criminalità in Russia: analisi del sistema. M., 1997.
19. Lee D.A. Contabilità statistica penale: modelli strutturali e funzionali. M.: Agenzia di informazione ed editoria "Russian World", 1998.
20. Makarova N.V., Trofimets V.Ya. Statistiche in Excel: Proc. indennità. M.: Finanza e statistica, 2009.
21. Nesterov L.I. Nuove tendenze nelle statistiche della ricchezza nazionale // Questioni di statistica. 2008. N. 11.
22. Petrova E.V. e altri Workshop sulle statistiche dei trasporti: Proc. indennità. M.: Finanza e statistica, 2008.
23. La criminalità in Russia negli anni Novanta e alcuni aspetti della legalità e il contrasto alla stessa. M., 1995.
24. Criminalità, statistica, diritto // Ed. prof. A.I. Debito. Mosca: Associazione criminologica, 1997.
25. Rostov K.T. La criminalità nelle regioni della Russia (analisi sociale e criminologica). San Pietroburgo: Accademia di San Pietroburgo del Ministero degli affari interni della Russia, 1998.
26. Linee guida per il censitore sulla procedura per condurre il censimento della popolazione tutta russa del 2002 e compilare i documenti del censimento. M.: PIK "Offset", 2003.
27. Savyuk L.K. Statistica giuridica: libro di testo. M.: Giurista, 1999.
28. Salin V.N., Shpakovskaya E.P. Statistiche socioeconomiche: libro di testo per le università. Mosca: Gardanika Avvocato, 2008.
29. Sidenko A.V., Popov G.Yu., Matveeva V.M. Statistica: libro di testo. Mosca: affari e servizi, 2008.
30. Prevenzione sociale dei reati: consigli, raccomandazioni // Ed. SÌ. Kerimov. M., 1989.
31. Statistica sociale: libro di testo per le università // Ed. I.I. Eliseeva. 3a ed. M.: Finanza e statistica, 2009.
Ospitato su Allbest.ru
Documenti simili
Considerazione dei principali metodi di analisi statistica. Studio del distretto municipale di Kungursky. Esecuzione di calcoli secondo gli indicatori dell'annuario. Analisi della demografia e dello sviluppo socio-economico dell'area sulla base dei risultati della domanda.
tesina, aggiunta il 24/06/2015
Il valore medio è una caratteristica libera delle regolarità del processo nelle condizioni in cui procede. Forme e metodi per il calcolo dei valori medi. Applicazione dei valori medi nella pratica: calcolo della differenziazione salariale per settori dell'economia.
tesina, aggiunta il 04/12/2007
Metodi statistici di analisi del divorzio. Analisi statistica dei divorzi nella regione dell'Amur. Analisi della dinamica e della struttura dei divorzi. Raggruppamento di città e distretti della regione dell'Amur in base al numero di divorzi all'anno. Calcolo dei valori medi e degli indicatori di variazione.
tesina, aggiunta il 04/12/2014
Aspetti di analisi statistica dell'offerta abitativa. Applicazione di metodi statistici per analizzare l'offerta di alloggi per la popolazione. Analisi dell'omogeneità della popolazione dei distretti in termini di fattore di carico demografico. Analisi di correlazione-regressione.
tesina, aggiunta il 18/01/2009
Organizzazione delle statistiche statali in Russia. Requisiti per i dati raccolti. Forme, tipi e metodi di osservazione statistica. Preparazione dell'osservazione statistica. Errori di osservazione statistica. Metodi per il monitoraggio delle statistiche.
abstract, aggiunto il 02.12.2007
Sviluppo di un programma di monitoraggio delle statistiche del diritto penale, delle sue principali fasi e requisiti, metodi e procedure per l'attuazione. Determinazione dello stato di criminalità nell'area di studio. Regole per la registrazione dei risultati dell'osservazione statistica.
test, aggiunto il 18/05/2010
Classificazione della documentazione statistica. Tipologie di documenti: scritti, iconografici, statistici e fonetici. Metodi e modalità di analisi dei materiali: non formalizzati (tradizionali) e formalizzati. La procedura per l'implementazione dell'analisi del contenuto.
presentazione, aggiunta il 16/02/2014
Il concetto di media. Il metodo delle medie nello studio dei fenomeni sociali. La rilevanza dell'applicazione del metodo delle medie nello studio dei fenomeni sociali è assicurata dalla possibilità di passare dal singolare al generale, dall'aleatorio al regolare.
tesina, aggiunta il 13/01/2009
Il concetto di osservazione statistica. Analisi delle correlazioni rettilinee e curvilinee. Conoscenza delle formule e dei valori dell'osservazione statistica. Analisi dei calcoli della relazione degli indici, costruzione di un istogramma, elementi di una serie di distribuzione.
test, aggiunto il 27/03/2012
Caratterizzazione dei principali indicatori dell'analisi statistica della condizionalità sociale della sanità pubblica nella Federazione Russa. Livelli di valutazione sanitaria dal punto di vista della medicina sociale. Classificazione della popolazione infantile per gruppi sanitari.
L'oggetto di studio nella statistica applicata sono i dati statistici ottenuti come risultato di osservazioni o esperimenti. I dati statistici sono una raccolta di oggetti (osservazioni, casi) e caratteristiche (variabili) che li caratterizzano. I metodi statistici di analisi dei dati sono utilizzati in quasi tutte le aree dell'attività umana. Vengono utilizzati ogni volta che è necessario ottenere e comprovare eventuali giudizi su un gruppo (oggetti o soggetti) con una certa eterogeneità interna.
I metodi di analisi statistica dei dati appartenenti al gruppo a) sono solitamente chiamati metodi di statistica applicata.
Le statistiche numeriche sono numeri, vettori, funzioni. Possono essere sommati, moltiplicati per coefficienti. Pertanto, nelle statistiche numeriche, varie somme sono di grande importanza. L'apparato matematico per analizzare le somme di elementi del campione casuale sono le leggi (classiche) dei grandi numeri e i teoremi limite centrale.
I dati statistici non numerici sono dati categorizzati, vettori di caratteristiche eterogenee, relazioni binarie, insiemi, insiemi fuzzy, ecc. Non possono essere sommati e moltiplicati per coefficienti.
L'analisi dei dati statistici, di norma, include una serie di procedure e algoritmi eseguiti in sequenza, in parallelo o secondo uno schema più complesso. In particolare si possono distinguere i seguenti passaggi:
pianificare uno studio statistico;
organizzare la raccolta dei dati statistici necessari secondo un programma ottimale o razionale (pianificazione del campione, creazione di una struttura organizzativa e selezione di un gruppo di statistici, formazione del personale che raccoglierà i dati, nonché dei responsabili del trattamento, ecc.);
raccolta diretta dei dati e loro fissazione su vari supporti (con controllo di qualità della raccolta e rifiuto di dati errati per motivi legati all'area tematica);
descrizione primaria dei dati (calcolo di varie caratteristiche del campione, funzioni di distribuzione, stime di densità non parametriche, costruzione di istogrammi, campi di correlazione, varie tabelle e grafici, ecc.),
stima di determinate caratteristiche numeriche o non numeriche e parametri di distribuzione (ad esempio, stima di intervalli non parametrici del coefficiente di variazione o ripristino del rapporto tra la risposta e i fattori, ovvero stima della funzione),
verifica di ipotesi statistiche (a volte le loro catene - dopo aver verificato l'ipotesi precedente, viene presa la decisione di verificare l'una o l'altra ipotesi successiva),
studio più approfondito, ad es. l'uso di vari algoritmi per analisi statistiche multivariate, algoritmi diagnostici e di classificazione, statistiche di dati non numerici e di intervallo, analisi di serie temporali, ecc.;
verifica della stabilità delle stime ottenute e delle conclusioni relative alle deviazioni ammissibili dei dati iniziali e alle ipotesi dei modelli probabilistico-statistici utilizzati, in particolare, lo studio delle proprietà delle stime mediante il metodo della moltiplicazione campionaria;
applicazione dei risultati statistici ottenuti per scopi applicativi (ad esempio, per diagnosticare materiali specifici, fare previsioni, scegliere un progetto di investimento dalle opzioni proposte, trovare la modalità ottimale per implementare il processo tecnologico, riassumere i risultati dei test su campioni di dispositivi tecnici , eccetera.),
preparazione di rapporti finali, in particolare, destinati a coloro che non sono specialisti in metodi statistici di analisi dei dati, anche per il management - "decisori".
I metodi includono:
Analisi di correlazione. Tra le variabili (variabili casuali) può esistere una relazione funzionale, manifestata nel fatto che una di esse è definita come funzione dell'altra. Ma tra le variabili può esserci anche un collegamento di altro tipo, manifestato nel fatto che una di esse reagisce al cambiamento dell'altra modificando la propria legge di distribuzione. Tale relazione è detta stocastica. Come misura della dipendenza tra variabili viene utilizzato il coefficiente di correlazione (r), che varia da -1 a +1. Se il coefficiente di correlazione è negativo significa che all’aumentare dei valori di una variabile diminuiscono i valori dell’altra. Se le variabili sono indipendenti, allora il coefficiente di correlazione è 0 (il viceversa è vero solo per le variabili che hanno una distribuzione normale). Ma se il coefficiente di correlazione non è uguale a 0 (le variabili si dicono incorrelate), allora significa che esiste una relazione tra le variabili. Quanto più il valore di r si avvicina a 1, tanto più forte è la dipendenza. Il coefficiente di correlazione raggiunge i suoi valori estremi di +1 o -1 se e solo se la relazione tra le variabili è lineare. L'analisi di correlazione consente di stabilire la forza e la direzione della relazione stocastica tra variabili (variabili casuali).
Analisi di regressione. L'analisi di regressione modella la relazione di una variabile casuale con una o più altre variabili casuali. In questo caso, la prima variabile è chiamata dipendente e il resto indipendente. La scelta o l'assegnazione delle variabili dipendenti e indipendenti è arbitraria (condizionata) e viene effettuata dal ricercatore a seconda del problema che sta risolvendo. Le variabili indipendenti sono chiamate fattori, regressori o predittori, mentre la variabile dipendente è chiamata caratteristica del risultato o risposta.
Se il numero di predittori è uguale a 1, la regressione è detta semplice, o univariata, se il numero di predittori è maggiore di 1, multipla o multifattoriale. In generale, il modello di regressione può essere scritto come segue:
y \u003d f (x 1, x 2, ..., x n),
dove y - variabile dipendente (risposta), x i (i = 1,…, n) - predittori (fattori), n - numero di predittori.
Analisi canonica. L'analisi canonica è progettata per analizzare le dipendenze tra due elenchi di caratteristiche (variabili indipendenti) che caratterizzano gli oggetti. Ad esempio, è possibile studiare la relazione tra vari fattori avversi e la comparsa di un determinato gruppo di sintomi di una malattia, oppure la relazione tra due gruppi di parametri clinici e di laboratorio (sindromi) di un paziente. L'analisi canonica è una generalizzazione della correlazione multipla come misura della relazione tra una variabile e molte altre variabili.
Metodi per confrontare le medie. Nella ricerca applicata, ci sono spesso casi in cui il risultato medio di alcune caratteristiche di una serie di esperimenti differisce dal risultato medio di un'altra serie. Poiché le medie sono i risultati delle misurazioni, quindi, di regola, differiscono sempre, la domanda è se la discrepanza osservata tra le medie possa essere spiegata dagli inevitabili errori casuali dell'esperimento o sia dovuta a determinati motivi. Il confronto dei risultati medi è uno dei modi per identificare le dipendenze tra caratteristiche variabili che caratterizzano l'insieme di oggetti studiati (osservazioni). Se, quando si dividono gli oggetti di studio in sottogruppi utilizzando una variabile indipendente categoriale (predittore), l'ipotesi sulla disuguaglianza delle medie di alcune variabili dipendenti nei sottogruppi è vera, ciò significa che esiste una relazione stocastica tra questa variabile dipendente e il predittore categorico.
Analisi della frequenza. Le tabelle di frequenza, o come vengono anche chiamate tabelle a voce singola, sono il metodo più semplice per analizzare le variabili categoriali. Questo tipo di studio statistico viene spesso utilizzato come una delle procedure di analisi esplorativa per vedere come sono distribuiti i diversi gruppi di osservazioni nel campione o come il valore di una caratteristica è distribuito nell'intervallo dal valore minimo a quello massimo. La tavola di contingenza (coniugazione) è il processo di combinazione di due (o più) tabelle di frequenza in modo che ciascuna cella nella tabella costruita sia rappresentata da un'unica combinazione di valori o livelli di variabili tabulate. La tavola di contingenza consente di combinare le frequenze di occorrenza delle osservazioni a diversi livelli dei fattori considerati.
Analisi della corrispondenza. L'analisi delle corrispondenze, rispetto all'analisi della frequenza, contiene metodi descrittivi ed esplorativi più potenti per analizzare tabelle a due e più vie. Il metodo, come le tabelle di contingenza, consente di esplorare la struttura e la relazione delle variabili di raggruppamento incluse nella tabella.
analisi di gruppo. L'analisi dei cluster è un metodo di analisi di classificazione; il suo scopo principale è quello di dividere l'insieme degli oggetti e delle caratteristiche oggetto di studio in gruppi o cluster in un certo senso omogenei. Questo è un metodo statistico multivariato, quindi si presuppone che i dati iniziali possano avere un volume significativo, ad es. sia il numero di oggetti di studio (osservazioni) che le caratteristiche che caratterizzano questi oggetti possono essere significativamente elevati. Il grande vantaggio dell'analisi cluster è che rende possibile partizionare gli oggetti non in base a un attributo, ma in base a un numero di attributi. Inoltre, l'analisi dei cluster, a differenza della maggior parte dei metodi matematici e statistici, non impone alcuna restrizione al tipo di oggetti in esame e consente di esplorare molti dati iniziali di natura quasi arbitraria.
Analisi discriminante. L'analisi discriminante include metodi statistici per classificare osservazioni multivariate in una situazione in cui il ricercatore dispone dei cosiddetti campioni di addestramento. Questo tipo di analisi è multidimensionale, poiché utilizza diverse caratteristiche dell'oggetto, il cui numero può essere arbitrariamente grande. Lo scopo dell'analisi discriminante è classificarlo, in base alla misurazione di varie caratteristiche (caratteristiche) di un oggetto, ad es. essere assegnato a uno dei numerosi gruppi (classi) dati in modo ottimale. Si presuppone che i dati iniziali, insieme alle caratteristiche degli oggetti, contengano una variabile categoriale (di raggruppamento) che determina se l'oggetto appartiene a un particolare gruppo. Analisi fattoriale. L’analisi fattoriale è uno dei metodi statistici multivariati più diffusi. Se i metodi cluster e discriminante classificano le osservazioni, dividendole in gruppi di omogeneità, allora l’analisi fattoriale classifica le caratteristiche (variabili) che descrivono le osservazioni. Pertanto, l'obiettivo principale dell'analisi fattoriale è ridurre il numero di variabili in base alla classificazione delle variabili e determinare la struttura delle relazioni tra loro.
Alberi di classificazione. Gli alberi di classificazione sono un metodo di analisi di classificazione che consente di prevedere l'appartenenza degli oggetti ad una particolare classe, a seconda dei valori corrispondenti delle caratteristiche che caratterizzano gli oggetti. Gli attributi sono chiamati variabili indipendenti e una variabile che indica se gli oggetti appartengono a classi è chiamata dipendente. A differenza dell'analisi discriminante classica, gli alberi di classificazione sono in grado di eseguire ramificazioni unidimensionali su variabili di vario tipo: categoriali, ordinali, di intervallo. Non vengono imposte restrizioni alla legge di distribuzione delle variabili quantitative. Il metodo, analogamente all'analisi discriminante, consente di analizzare i contributi delle singole variabili alla procedura di classificazione.
Analisi e classificazione delle componenti principali. Il metodo di analisi e classificazione delle componenti principali consente di risolvere questo problema e serve a raggiungere due obiettivi:
ridurre il numero totale di variabili (riduzione dei dati) al fine di ottenere variabili “principali” e “non correlate”;
classificazione delle variabili e delle osservazioni, utilizzando lo spazio dei fattori costruito.
La soluzione del problema principale del metodo si ottiene creando uno spazio vettoriale di variabili (fattori) latenti (nascoste) con una dimensione inferiore a quella originale. La dimensione iniziale è determinata dal numero di variabili per l'analisi nei dati di origine.
Scala multidimensionale. Il metodo può essere visto come un'alternativa all'analisi fattoriale, che ottiene una riduzione del numero di variabili estraendo fattori latenti (non osservati direttamente) che spiegano le relazioni tra le variabili osservate. Lo scopo del ridimensionamento multidimensionale è trovare e interpretare variabili latenti che consentano all'utente di spiegare le somiglianze tra oggetti dati punti nello spazio delle caratteristiche originali. In pratica, indicatori della somiglianza degli oggetti possono essere le distanze o i gradi di connessione tra loro. Nell'analisi fattoriale, le somiglianze tra le variabili sono espresse utilizzando una matrice di coefficienti di correlazione. Nello scaling multidimensionale, un tipo arbitrario di matrice di somiglianza degli oggetti può essere utilizzato come dati di input: distanze, correlazioni, ecc.
Modellazione mediante equazioni strutturali (modellazione causale). Oggetto della modellazione delle equazioni strutturali sono i sistemi complessi, la cui struttura interna non è nota ("scatola nera"). L'idea principale della modellazione di equazioni strutturali è che è possibile verificare se le variabili Y e X sono correlate da una relazione lineare Y = aX analizzando le loro varianze e covarianze. Questa idea si basa su una semplice proprietà della media e della varianza: se moltiplichi ciascun numero per una costante k, anche la media verrà moltiplicata per k, con la deviazione standard moltiplicata per il modulo di k.
Serie temporali. Le serie temporali sono l'area più promettente e in via di sviluppo della statistica matematica. Una serie temporale (dinamica) è una sequenza di osservazioni di un certo attributo X (variabile casuale) in successivi momenti equidistanti t. Le singole osservazioni sono chiamate livelli della serie e sono indicate con xt, t = 1, ..., n. Quando si studia una serie storica, si distinguono diverse componenti:
x t \u003d u t + y t + c t + e t, t \u003d 1, ..., n,
dove u t è una tendenza, una componente in costante cambiamento che descrive l'impatto netto di fattori a lungo termine (declino della popolazione, calo del reddito, ecc.); - componente stagionale, che riflette la frequenza dei processi su un periodo non molto lungo (giorno, settimana, mese, ecc.); сt - componente ciclica, che riflette la frequenza dei processi su lunghi periodi di tempo nell'arco di un anno; t è una componente casuale che riflette l'influenza di fattori casuali che non possono essere contabilizzati e registrati. I primi tre componenti sono componenti deterministici.
Reti neurali. Le reti neurali sono un sistema informatico la cui architettura è analoga alla costruzione del tessuto nervoso a partire dai neuroni. Ai neuroni dello strato più basso vengono forniti i valori dei parametri di input, sulla base dei quali devono essere prese determinate decisioni.
Pianificazione dell'esperimento. L'arte di disporre le osservazioni in un certo ordine o di effettuare controlli appositamente pianificati per sfruttare appieno le possibilità di questi metodi è il contenuto della materia "progettazione sperimentale".
Carte di controllo qualità. La qualità dei prodotti e dei servizi si forma nel processo di ricerca scientifica, progettazione e sviluppo tecnologico, ed è assicurata da una buona organizzazione della produzione e dei servizi. Ma la fabbricazione di prodotti e la fornitura di servizi, indipendentemente dalla loro tipologia, sono sempre associati ad una certa variabilità nelle condizioni di produzione e fornitura. Ciò porta ad una certa variabilità nelle caratteristiche della loro qualità. Pertanto, sono rilevanti le questioni legate allo sviluppo di metodi di controllo della qualità che consentano il rilevamento tempestivo di segni di violazione del processo tecnologico o della fornitura di servizi.
Varie unità della popolazione statistica, che hanno una certa somiglianza tra loro in termini di caratteristiche sufficientemente importanti, vengono combinate in gruppi utilizzando il metodo del raggruppamento. Questa tecnica consente di "comprimere" le informazioni ottenute nel corso dell'osservazione e su questa base di stabilire schemi inerenti al fenomeno in studio.
Il metodo del raggruppamento viene utilizzato per risolvere vari problemi, i più importanti dei quali sono:
1. assegnazione delle tipologie socioeconomiche
2. Determinazione della struttura di collezioni simili
3. rivelare collegamenti e modelli tra caratteristiche individuali dei fenomeni sociali
A questo proposito, ci sono 3 tipi di raggruppamenti: tipologico, strutturale e analitico. I raggruppamenti si distinguono per la forma di condotta.
Il raggruppamento tipologico è la divisione della popolazione statistica qualitativamente eterogenea indagata in classi, tipologie socioeconomiche, gruppi omogenei di unità.
I raggruppamenti strutturali dividono un insieme qualitativamente omogeneo di unità secondo alcune caratteristiche essenziali in gruppi che ne caratterizzano la composizione e la struttura interna.
I raggruppamenti analitici assicurano l'instaurazione della relazione e dell'interdipendenza tra i fenomeni socioeconomici studiati e le caratteristiche che li caratterizzano. Mediante questo tipo di raggruppamento si stabiliscono e studiano le relazioni causali tra i segni di fenomeni omogenei e si determinano i fattori per lo sviluppo di una popolazione statistica.
Sotto metodi di analisi statistica si riferisce alle tecniche di matematica applicata, che vengono utilizzate per aumentare l'obiettività e l'affidabilità dei dati ottenuti, per elaborare i risultati sperimentali. Nella psicologia differenziale, tre di questi metodi vengono spesso utilizzati: dispersione, correlazione e analisi fattoriale.
1. Analisi della varianza consente di determinare la misura della variazione individuale degli indicatori (poiché è noto che con gli stessi indicatori medi l'intervallo di distribuzione può differire in modo significativo). Per alcune ricerche e problemi pratici, è la dispersione a fornire l’informazione principale. Ad esempio, immagina che il punteggio medio ottenuto dagli scolari in un test di algebra sia "4" sia per i ragazzi che per le ragazze. Ma i ragazzi hanno sia tripli che cinque, e tutte le ragazze si sono tradite attivamente a vicenda e di conseguenza ne hanno ricevute quattro. È chiaro che il risultato è lo stesso in ogni gruppo, ma il significato psicologico e pedagogico dietro il punteggio medio è completamente diverso.
2. Analisi di correlazione certifica l'esistenza di una connessione, dipendenza tra le variabili studiate. Ciò conferma la simultaneità della manifestazione di questi segni, ma non la loro causalità. Se due caratteristiche qualsiasi ottenute per lo stesso oggetto tendono a cambiare insieme, in modo che sia possibile prevedere una di esse dal valore dell'altra, allora queste caratteristiche si dicono correlate tra loro. Ad esempio, si nota che la soddisfazione coniugale tra i coniugi è negativamente correlata all'ansia. Ciò significa che quanto più sono soddisfatti della vita familiare, tanto più si sentono rilassati. Tuttavia, sulla base di questo fatto, non possiamo sapere se sono tranquilli perché a casa tutto è in ordine, o se sono soddisfatti della loro vita insieme perché hanno poca ansia e un atteggiamento complessivamente positivo nei confronti della vita.
Matematicamente, la presenza di una relazione tra caratteristiche è espressa in termini di coefficiente di correlazione: due caratteristiche identiche sono interconnesse dal coefficiente "1"; due diversi - dal coefficiente "0". Il grado di parentela delle caratteristiche è compreso tra 0,01 e 0,99. Le correlazioni prossime allo zero non possono confermare l'esistenza di una relazione tra variabili. Il rapporto può essere positivo (+1) o negativo (-1). Un coefficiente di correlazione negativo significa che all’aumentare del valore di una caratteristica, il valore dell’altra caratteristica diminuisce. È stato proposto il coefficiente di correlazione Carlo Spearmann misurare la relazione tra due indicatori intellettuali (1901). Una scoperta simile è stata fatta da uno degli studenti di F. Galton Karl Pearson.
3. Analisi fattorialeè un gruppo di metodi progettati per determinare proprietà che non possono essere osservate e misurate direttamente. L'idea dell'analisi fattoriale appartiene a K. Spearman, che ha proposto di identificare modelli generali basati sull'analisi della matrice dei coefficienti di correlazione. Nel caso in cui, in base ai risultati del calcolo dei coefficienti di correlazione, vengano tracciate relazioni particolarmente dense tra diversi indicatori (correlazione pleiadi), si può presumere che dietro di essi vi sia un fattore comune: una variabile di un livello di generalizzazione più elevato.
Utilizzando questo metodo di strutturazione e generalizzazione delle informazioni psicologiche, diventa possibile ottenere una descrizione compatta dell'oggetto di misurazione, per evidenziare le caratteristiche più significative e indipendenti. Questa funzionalità consente di utilizzare l'analisi fattoriale per risolvere i seguenti problemi psicodiagnostici:
- "pulizia concettuale" (chiarimento del contenuto psicologico dei fenomeni studiati);
Progettazione delle prove;
Verifica delle proprietà psicometriche dei questionari (soprattutto quando i questionari vengono utilizzati in nuove culture o popolazioni).
Nella psicologia differenziale, i metodi di analisi fattoriale sono ampiamente utilizzati nello studio della struttura dell'individualità, nonché delle sue componenti individuali, come il temperamento, l'intelligenza e la personalità. I fattori identificati sono considerati proprietà stabili e relativamente indipendenti che caratterizzano la struttura oggetto di studio.
Allo stesso tempo, vengono presi in considerazione diversi livelli di generalizzazione delle informazioni, in base ai quali si distinguono tre tipi di fattori:
Fattori generali che combinano tutte le dimensioni di una determinata proprietà, ad esempio un fattore di intelligenza generale o un fattore di attività generale;
Fattori di gruppo, che includono non tutte, ma un numero significativo di dimensioni di una determinata proprietà;
Fattori specifici o unici relativi a un solo tipo di misurazione.
Come limite dell’analisi fattoriale, vale la pena notare la relativa soggettività dei suoi metodi. I risultati della fattorizzazione dipendono dalla natura e dal numero delle variabili analizzate. La decisione di scegliere la forma di analisi fattoriale e le variabili da includere nella matrice originale viene presa sulla base di questi parametri, nonché delle posizioni teoriche di ciascun ricercatore. Di conseguenza, vengono creati modelli di individualità che differiscono non solo per il numero di fattori identificati, ma anche per la natura delle relazioni che si trovano tra loro.
Secondo il ricercatore polacco Jan Strelyau, l’uso di questo metodo presenta notevoli difetti. Autori diversi hanno quantità e qualità diverse dei fattori assegnati, sebbene il materiale di partenza che costituisce la base per la selezione dei fattori rimanga invariato. Di norma, i ricercatori non sono d'accordo già sul punto di partenza: la scelta dei dati oggetto dell'analisi fattoriale. Ciò porta al fatto che il contenuto delle distinte strutture dell'individualità differisce significativamente l'uno dall'altro. Il difetto sta nel metodo stesso, che è arbitrario e dipende dall'intuizione e dalla perseveranza del ricercatore.
Per utilizzare correttamente i metodi di analisi statistica, è necessario essere sicuri della normale distribuzione della qualità studiata.
Distribuzione normaleè apparso grazie alla ricerca dell'intelligence. F. Galton fu il primo a scoprire che le differenze di intelligenza possono essere quantificate stabilendo il grado di gravità di queste caratteristiche in persone diverse. Ha suggerito che queste differenze sono normalmente distribuite nella popolazione, cioè piccoli gruppi di persone hanno un livello di intelligenza alto (14%) o basso (14%) e la maggioranza del campione (68%) è nel mezzo (1869). Le manifestazioni estreme rappresentano il 4% (2% per ciascun polo).
In una rappresentazione grafica, una distribuzione normale ha la forma di una cupola: i singoli valori di una variabile sono disposti simmetricamente rispetto al centro. In questo caso, il valore centrale coincide con la mediana - il punto sopra il quale si trova esattamente la metà delle variabili, e sotto - anch'esso esattamente la metà.
Insieme alla distribuzione normale, si incontrano spesso distribuzioni asimmetriche e bimodali. Tuttavia, anche con una distribuzione normale, esiste la possibilità che i risultati ottenuti siano casuali. Questa probabilità si chiama "livello di significatività". Ad esempio, nonostante i valori elevati, il coefficiente di correlazione può avere un diverso livello di significatività, fino a "zero". Il livello di significatività dipende dalla dimensione del campione e dalla diffusione dei valori.
Allo stesso modo, punteggi diversi o simili non sono sempre statisticamente significativi. Esistono diversi modi per identificare il significato delle differenze. La loro scelta dipende dalla natura della distribuzione dei dati sperimentali, dalla dipendenza o dall'indipendenza delle variabili, nonché dal grado di accuratezza richiesta, che è determinata dagli obiettivi dello studio.
- In contatto con 0
- Google Plus 0
- OK 0
- Facebook 0